Data Catalog vs. Data Dictionary: 5 Essential Differences

Table of Contents
Much like a confused tourist trying to differentiate between an alligator and a crocodile from a safe distance, you might squint at a data catalog vs. data dictionary and wonder, “Aren’t they just two boring lists of data stuff?”
Well, no. In fact, not at all. And the distinction isn’t just pedantic, it’s profoundly practical. A data dictionary acts like a meticulous librarian cataloging every book by its exact place and content, focusing narrowly on the particulars of individual data stores. Meanwhile, a data catalog is like a bustling city planner, mapping out where each library sits in the city and how they connect through a network of roads, traffic lights, and underground pipes.
In other words, a data catalog is a comprehensive tool for managing and discovering an organization’s data assets across multiple systems, featuring search capabilities, metadata management, and governance tools, whereas a data dictionary is a focused reference that provides detailed information about the data elements within a specific database or system, including their names, types, and descriptions.
Navigating these differences is essential for any organization aiming to optimize their data infrastructure for clarity, compliance, and collaboration. Let’s decode these critical tools, unbundling the essential differences in purpose, content, usage, maintenance, and governance of a data catalog vs. data dictionary.
Table of Contents
1. Purpose
A data dictionary serves a micro purpose by offering deep, precise documentation for data within a single database. It functions like a detailed catalog that tracks every item in one library. It provides clarity, consistency, and structure to those working directly with that specific data environment. A data dictionary helps engineers, DBAs, and developers know exactly what each column means, what values are valid, and how fields relate. For instance, a sales database dictionary might specify that “Customer_ID” is an integer, unique, and represents a client in the CRM. That’s immensely helpful when building queries or data pipelines.
In contrast, a data catalog is zoomed out. Instead of looking at one library, it maps all the libraries across a city. Its role is to help users find, understand, and access data across a wide variety of data sources such as warehouses, lakes, APIs, and file stores. It connects technical metadata such as schema with business-friendly context, including who owns the data, how it’s used, how fresh it is, and how it relates to other assets. This makes it a trusted resource for data discovery and governance across the entire organization.
This difference in focus matters because organizations need both tools working together. One offers depth, the other offers reach. A data dictionary brings accuracy to the source. Data catalogs bring visibility across the landscape.
2. Content
A data dictionary captures deep technical detail about specific data assets. It includes structured definitions for each table and column, covering names, data types, formats, allowed values, and relationships between fields. This level of documentation ensures that engineers and developers have precise guidance when building pipelines, writing queries, or maintaining database structure. For example, a dictionary entry might note that a column labeled Order_Date must follow a YYYY-MM-DD format and cannot be null. These are the specs that help teams use data accurately within a single environment.
A data catalog holds all of that detail and expands it. It aggregates technical metadata from many sources, but it also layers on business context. That includes human-readable descriptions of what a dataset is used for, data lineage that shows where data originated and how it flows through the stack, data quality metrics based on completeness and freshness, and ownership details. Users can also add community-generated metadata such as tags, annotations, and trust ratings. In short, catalogs give people a way to find, understand, and evaluate data no matter where it lives.
The contrast is clear. A data dictionary explains what a column means in one database. A data catalog shows where to find the dataset, how to request access, how it’s connected to other data, and whether the organization considers it trustworthy. This added layer of meaning and context is what makes catalogs critical for self-service analytics, governance, and collaboration. While data dictionaries are exhaustive, they are limited in scope. Data catalogs bring the bigger picture into focus.
3. Usage
A data dictionary is primarily used by technical teams. These include data engineers designing pipelines, developers writing queries, and database administrators managing schemas. Their goal is precision. They need to understand exactly what each column means, what values are valid, and how different fields relate. The dictionary provides that clarity. It answers questions like whether a status field includes archived records or whether a timestamp column allows nulls. These are the kinds of details that affect transformations, integrations, and downstream reliability.
On the other hand, a data catalog is built for a much wider group. Yes, data engineers and technical users rely on it too. But so do analysts, data scientists, compliance officers, and product teams. Business users use it to find data relevant to a KPI. Analysts browse it to locate trusted customer churn datasets. Data scientists scan it to check freshness before using a dataset for model training. Even governance teams use it to see which datasets include sensitive information.
The broader utility of the catalog is what makes it essential for modern data operations. It supports self-service discovery by giving users the information they need to evaluate a dataset before even opening it. Lineage, descriptions, usage stats, and access controls all help someone decide whether a dataset is fit for use. By contrast, the dictionary is more of a backstage resource for those maintaining the plumbing.
This difference matters because it highlights a gap many teams face. If only technical users can interpret the data documentation, then discovery and understanding slow down. A catalog addresses that by making data searchable, contextual, and accessible to everyone. When used together, dictionaries and catalogs give both the technical depth and organizational reach that teams need to build trust in data.
4. Maintenance
A data dictionary is typically created and maintained by hand. Someone writes it, often using spreadsheets or a documentation tool, and then updates it as changes happen. This sounds simple, but in practice it rarely keeps pace. Schemas evolve. New columns are added. Old ones are deprecated. Without a dedicated process, the dictionary drifts out of sync with reality. Even in cases where metadata is embedded in the database, upkeep still depends on someone manually curating and validating the content.
This manual approach has real drawbacks. If a dictionary is outdated, it loses trust. And in dynamic environments where data is constantly changing, stale documentation is a liability. Teams may avoid using it altogether or operate with false assumptions about what a field means or whether it even still exists.
A data catalog flips this on its head. It uses automated crawlers to scan and ingest metadata across the data stack. That includes table structures, column details, lineage, usage patterns, and more. This scanning can happen on a schedule or in response to events, ensuring the catalog reflects the current state of the data landscape. When a new table appears in the warehouse, it shows up in the catalog without someone needing to create an entry. When column definitions change, those changes get reflected in the interface.
That’s only part of the story. A catalog also supports user-driven updates. Owners can add context. Analysts can tag trusted datasets. Governance teams can flag sensitive data. All of this happens collaboratively and asynchronously, allowing the catalog to grow and evolve with the organization.
The result is a living index that scales as data grows. A data dictionary might be accurate today, but a data catalog stays accurate every day. That difference becomes more important as data volumes rise and teams expand. Automation is no longer a nice-to-have. It’s the only way to manage metadata at scale.
5. Governance
A data dictionary acts as a static reference point. It provides definitions and structure for how data is described, but it does not actively enable collaboration or governance. Teams may consult it for consistency, but it is rarely used to enforce access policies or data usage rules. It documents terms, maybe ownership, but not access controls or compliance workflows. In many cases, only a small group maintains it. Everyone else reads, but cannot contribute. The result is a tool that is valuable but limited in reach and participation.
A data catalog changes this dynamic. It allows collaboration by design. Teams can comment on datasets, tag key fields, flag issues, and update descriptions with real-time input. Data stewards can certify trusted datasets. Business users can ask questions right inside the platform. Ownership is clear and shared, not siloed. Governance also becomes more visible. Many catalogs include access control integrations and usage tracking. Users can see who can access a dataset, what policies apply, and whether sensitive information is involved. This transparency supports regulatory compliance and internal controls.
This shift from passive reference to active hub is what makes the catalog so powerful. It does not just describe the data. It creates a shared understanding across teams. It also integrates with broader data governance initiatives by surfacing the right metadata in the right context. Many organizations even embed their data dictionary definitions within the data catalog, bringing the best of both together in one place. In practice, the data catalog becomes the front door to data across the business.
Do You Need Both, and How Do They Work Together?
Given these differences, a logical question is: “Which one does my organization need, or do we need both a data dictionary and a data catalog?” The answer in many cases is both, but not as separate, redundant efforts. Instead, they are complementary components of a unified data management strategy.
In practice, data dictionaries often feed into data catalogs. You can think of the relationship in this way. The data dictionary for a database provides the detailed ingredients and the data catalog compiles the cookbook that tells everyone what is available to cook. A modern data catalog will typically incorporate the schema information for each data source it covers, usually by automated metadata scanning. This means you do not have to maintain two completely separate inventories of your data’s details. Instead, you maintain the dictionaries and the catalog ingests those details and adds the broader context around them.
Many organizations start with data dictionaries as a first step. As the data ecosystem grows, they then introduce a data catalog to bring it all together. The data catalog becomes an umbrella that includes technical documentation and links it with business documentation and social elements. In fact, one recent industry trend is that the distinction between catalogs and dictionaries is fast vanishing, as catalog tools now automatically crawl and include data dictionary metadata as part of their catalog. Rather than choosing one or the other, companies focus on the capabilities they need.
That said, it is still important to understand the difference, because you might hear the terms used in different contexts. If a vendor says their product has a “data dictionary”, they usually mean the technical metadata repository aspect. If they say “data catalog”, they imply a more feature-rich platform with search and governance. In conversation, if someone asks “Do we have a data dictionary for our CRM database?”, they are likely asking for a document about that schema. If someone asks “Do we have a data catalog for the company?”, they are asking if there is a centralized tool to search across data sources.
In summary, most organizations will leverage both. The data dictionary ensures each system’s data is well-defined, while the data catalog ensures anyone in the organization can find and understand the data they need. They work in tandem.
Both data catalogs and data dictionaries need data observability
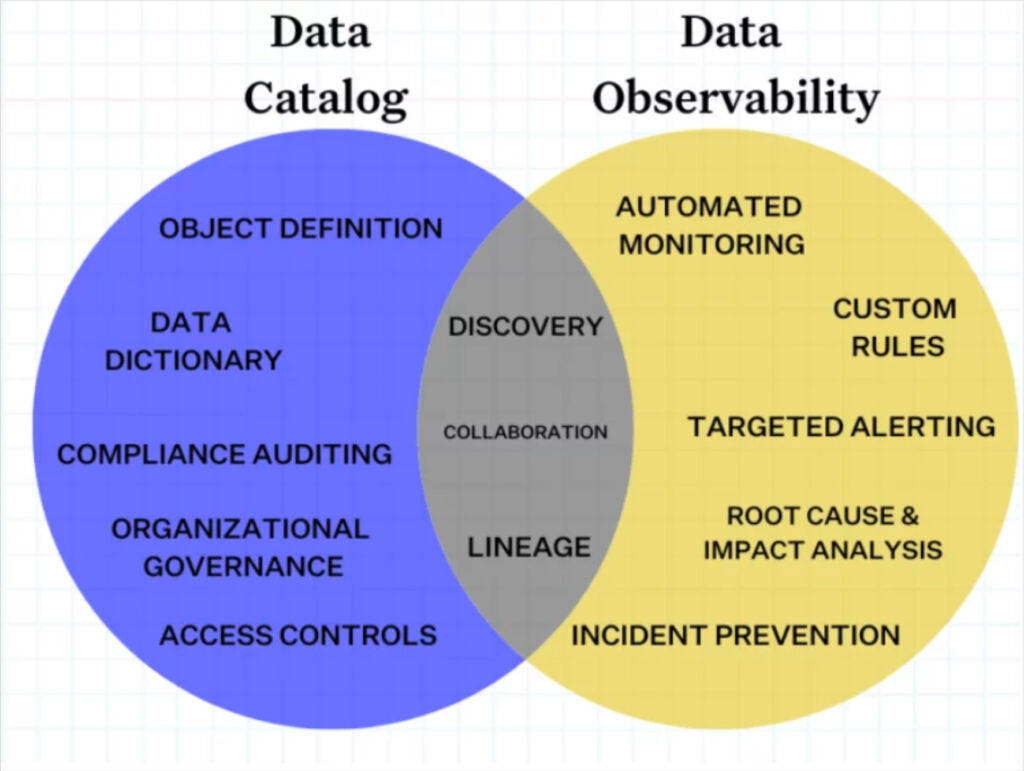
Data observability plays a crucial role in enhancing the functionality and value of data dictionaries and data catalogs by ensuring the health of your data.
A data observability platform like Monte Carlo monitors, diagnoses, and resolves data quality issues in real-time. Think of it as a dynamic layer that complements the static nature of data dictionaries and the broad oversight of data catalogs. It ensures that the data described in dictionaries and indexed in catalogs is accurate, reliable, and governed effectively.
Ready to see how observability can transform your data management strategy? Request a demo today and witness firsthand the impact of data observability on your organization’s efficiency and decision-making capabilities.
Our promise: we will show you the product.





