RAG vs Fine Tuning: How to Choose the Right Method

Table of Contents
Generative AI has the potential to transform your business and your data engineering team, but only when it’s done right. So how can your data team actually drive value with your LLM or GenAI initiative?
Leading organizations are often deciding between two emerging frameworks that differentiate their AI for business value: RAG vs fine tuning.
What’s the difference between retrieval augmented generation (RAG) vs fine tuning? And when should your organization choose RAG vs fine tuning? Should you use both?
We’ll dive into the fundamentals of RAG vs fine tuning, when each method is best, their benefits, and a few real-world use cases to get you started.
Table of Contents
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is an approach that connects a large language model to an external knowledge source or database. Traditional language models rely solely on the text they were trained on, which means their knowledge is frozen at a specific point in time. Once training ends, they cannot update their information or access new data, similar to someone trying to answer current events questions using only an old encyclopedia. This limitation led Meta AI researchers to introduce RAG in 2020 as a solution.
RAG fundamentally changes how these AI models work by allowing them to fetch relevant information at query time, the exact moment when someone asks a question. Instead of generating responses purely from their training data, RAG implementations first search through their connected databases for pertinent information. They then provide this information to the language model, which uses it to ground its answer in current, accurate data. This process happens seamlessly and quickly, combining the model’s natural language abilities with real-time information retrieval.
The practical implications are significant. If you ask a traditional language model about yesterday’s stock prices or a company’s latest earnings report, it can only guess based on outdated patterns in its training data. A RAG-powered model, however, would search its connected database for the most recent financial information and deliver an accurate, timely response. This approach transforms AI applications from static knowledge repositories into dynamic tools that can access and incorporate fresh information whenever needed.
RAG development is a complex process, and it doesn’t exist in a vacuum. It can involve prompt engineering, vector databases like Pinecone, embedding vectors and semantic layers, data modeling, data orchestration, and data pipelines – all tailored for RAG.
How a RAG flow works
The RAG pipeline follows a straightforward sequence that transforms a simple question into an informed response. When a user asks a question, the technology doesn’t immediately start generating an answer. Instead, it first searches a connected knowledge base for relevant content. This knowledge base could be company documents, a curated database, scientific papers, or any other collection of information that the organization has made searchable.
RAG uses various techniques to find the most relevant information, typically converting both the user’s question and the stored documents into numerical representations that can be compared for similarity. It then retrieves the most pertinent snippets of text or data. These retrieved pieces of information are combined with the user’s original query to create an enhanced prompt. This augmented prompt, containing both the question and the relevant context, is then fed into the large language model.
The process can be summarized in four clear steps. First, the user submits their query. Second, RAG retrieves relevant data from the knowledge base. Third, it combines this retrieved information with the original prompt. Fourth, the LLM generates a response using both its trained knowledge and the provided context. This pipeline ensures that the model’s output is augmented by real-time data, allowing it to provide answers that are both well-written and factually grounded.

So, developing a RAG architecture is a complex undertaking for your data team, and it requires the development of data pipelines to serve the proprietary contextual data that augments the LLM. But when it’s done right, RAG can add an incredible amount of value to AI-powered data products.
Key benefits of RAG
RAG transforms how language models handle information by giving them access to external data sources, which dramatically improves the quality and reliability of their outputs. The following benefits make RAG particularly valuable for organizations and developers working with AI.
Access to up-to-date, specific information
Because the model can consult current databases and documents, answers can include up-to-date, specific information not originally in the model’s training set. A financial analyst querying quarterly earnings data receives the latest figures rather than outdated estimates. A lawyer searching for recent case precedents gets current rulings instead of historical patterns. This capability directly addresses one of the most significant limitations of traditional language models, transforming them from static knowledge repositories into dynamic information tools.
Reduced hallucinations
RAG substantially reduces two common AI problems. First, it eliminates the staleness issue where models provide outdated information simply because their training data is frozen in time. Second, it minimizes hallucination, where models confidently generate plausible-sounding but incorrect facts about topics they don’t actually know. When a RAG-enabled model lacks information about a specific topic, it searches for real data rather than inventing details. This grounding in actual sources makes the technology far more reliable for professional and business applications.
Enhanced security
RAG enhances security and privacy for enterprise use in ways that traditional fine-tuning cannot match. Proprietary data isn’t embedded into the model itself but stays in a secure database under the organization’s control. Companies can update, remove, or restrict access to sensitive information without retraining the entire model. This separation means that confidential customer data, trade secrets, or internal strategies remain protected within existing security infrastructure while still being accessible to authorized AI queries.
Traceability and verification
Perhaps most importantly, RAG enables traceability throughout the answer generation process. Users can often trace responses back to specific source documents, creating an audit trail that proves invaluable for verifying accuracy and debugging errors. If an answer seems questionable, you can examine exactly which documents the model consulted and determine whether the issue lies in the source material, the retrieval process, or the interpretation. This transparency builds trust and makes it easier to improve the technology over time.
Challenges of RAG
While RAG offers significant advantages over traditional language models, implementing it isn’t “free” of effort. Organizations must consider several technical and operational challenges before deploying RAG solutions. These complexities require careful planning and ongoing maintenance to ensure the technology delivers on its promise.
Building and maintaining retrieval infrastructure
RAG requires building and maintaining a sophisticated retrieval infrastructure that goes well beyond simply connecting a database to a language model. Teams need to set up data pipelines to ingest and process documents, implement indexing in a vector database to enable semantic search, and create a search mechanism to fetch relevant text quickly and accurately. This infrastructure must handle various document formats, maintain data quality, and scale with growing knowledge bases. Unlike traditional applications where you might simply query a SQL database, RAG requires specialized tools and expertise in embedding models, similarity search, and distributed computing.
Engineering complexity and performance optimization
The engineering complexity extends to continuously updating the knowledge base while ensuring fast query response times. Every new document added to the knowledge base must be processed, embedded, and indexed without disrupting ongoing operations. Teams must balance retrieval accuracy with speed, often implementing caching strategies and query optimization techniques. Performance becomes particularly challenging at scale when dealing with millions of documents and hundreds of concurrent users. Organizations frequently discover that what works in a proof-of-concept fails when deployed to production environments with real-world data volumes and user loads.
Context window limitations
The LLM is fundamentally limited by its prompt length, creating a significant constraint for RAG implementations. All retrieved context must fit into the model’s context window along with the user’s query and any additional instructions. When relevant information spans multiple lengthy documents, the retrieved content must be chunked and filtered to include only the most pertinent pieces. This requires sophisticated algorithms to determine relevance, maintain coherence when splitting documents, and ensure critical information isn’t lost in the filtering process. Poor chunking strategies can lead to incomplete or misleading answers, even when the correct information exists in the knowledge base.
Example use-case
To understand RAG’s practical value, consider how organizations are using this technology to solve real business problems. These examples demonstrate how RAG transforms generic AI models into specialized tools that access and leverage proprietary information.
Imagine a company internal chatbot that answers employees’ HR or IT questions. Without RAG, such a chatbot would struggle to provide accurate information about company-specific policies or procedures. Using RAG, however, the chatbot can search the company’s internal documentation including wikis, policy documents, and knowledge base articles whenever a question comes in.
If an employee asks, “How do I reset my VPN password?”, the RAG-enabled chatbot searches through IT documentation and retrieves the relevant help page snippet containing the specific steps for that company’s VPN solution. It then feeds this information to the language model, which produces an answer with the exact steps, complete with any company-specific requirements or systems. This ensures employees receive accurate, current guidance rather than generic advice that might not apply to their organization’s setup.
The same principle applies across industries. A financial advisor assistant using RAG could fetch the latest stock prices, news, or a client’s portfolio data to give real-time investment advice. When a client asks about rebalancing their portfolio, the assistant retrieves current market data, the client’s holdings, and recent financial news relevant to their investments. This real-time information retrieval enables personalized, timely advice that would be impossible with a static model.
These examples highlight how RAG bridges the gap between general-purpose AI and specialized business needs. Rather than attempting to train models on every possible piece of proprietary information, organizations can maintain their data in existing formats while giving AI the ability to access and utilize it intelligently. This approach proves particularly valuable in regulated industries or situations where information changes frequently, making traditional model training impractical or impossible.
RAG vs AI Agents
The next level in sophistication is an agentic workflow where LLMs not only reference data, but use tools in a loop to accomplish a particular task.

What is fine tuning?
Fine-tuning means taking a pre-trained language model and further training it on a specific, targeted dataset to adjust its weights for a particular task or domain. While the original model learned from vast amounts of general text during pre-training, fine-tuning exposes it to carefully selected examples that teach it to excel at specialized tasks. This process fundamentally changes how the model processes and generates text, making it more adept at handling specific types of content or following particular patterns.
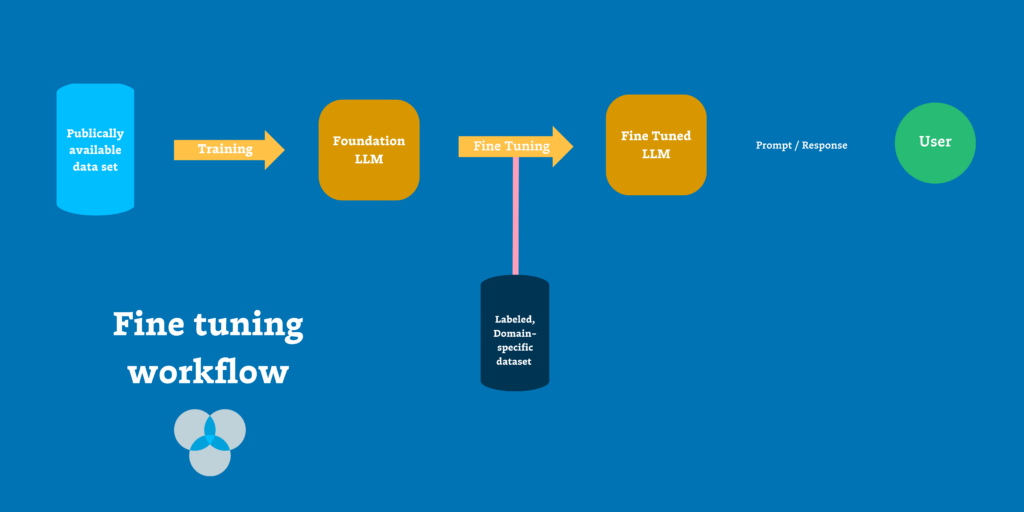
During fine-tuning, the model essentially “learns” from new examples so it can produce more specialized or accurate outputs relevant to a certain domain. A general-purpose model might struggle with medical terminology or legal language, but after fine-tuning on medical journals or legal documents, it becomes fluent in these specialized vocabularies and writing styles. The neural network adjusts its internal parameters based on these domain-specific examples, developing new capabilities while retaining much of its original knowledge.
Fine-tuning is typically done after the initial pre-training phase and represents a form of transfer learning that narrows the model’s focus. Rather than starting from scratch, developers leverage the broad understanding the model gained during pre-training and refine it for specific applications. This approach proves far more efficient than training a specialized model from the ground up, requiring less data and computational resources while often achieving better results. The process can transform a jack-of-all-trades AI into a domain expert, whether that domain is customer service, code generation, or creative writing.
How fine tuning works
The fine-tuning process begins with a large general-purpose model like GPT-3 or another foundation model that already understands language broadly. Developers then prepare a curated dataset relevant to their specific task. This dataset might contain thousands of legal documents for a law firm’s AI assistant, medical Q&A pairs for a healthcare application, or customer support transcripts for a service chatbot. The quality and relevance of this dataset directly determines how well the fine-tuned model will perform.
Through supervised training, the model is re-trained on this new data, adjusting its internal parameters to better fit the patterns in the fine-tuning dataset. Each example in the dataset teaches the model what good outputs look like for that domain. The training process feeds these examples through the neural network repeatedly, calculating errors between the model’s predictions and the desired outputs, then adjusting the model’s weights to reduce these errors. This continues for many training iterations until the model reliably produces the desired outputs.
Over time, the model specializes in remarkable ways. It learns domain-specific terminology that rarely appeared in its original training, adopts the writing style common to that field, and internalizes facts present in the fine-tuning data. A model fine-tuned on radiology reports starts using medical terminology precisely and structures its outputs like actual radiologist notes. One trained on legal contracts begins generating text with appropriate clauses, citations, and formal language expected in legal documents.
Modern fine-tuning can be full, where all model weights are updated, or parameter-efficient, where only certain layers are modified or small adapter modules are added. Techniques like LoRA (Low-Rank Adaptation) or other PEFT (Parameter-Efficient Fine-Tuning) methods can achieve similar results while using a fraction of the computational resources. These approaches add small trainable components to the model while keeping most original weights frozen, making fine-tuning accessible to organizations without massive computing budgets.
The result is a new version of the model that functions as an expert in the given domain or task. This specialized model retains much of its general knowledge but now excels at the specific application it was fine-tuned for, producing outputs that match the style, terminology, and requirements of that particular field.
Key benefits of fine tuning
Fine-tuning offers distinct advantages that make it the preferred approach for many specialized AI applications. By adjusting the model’s internal weights through targeted training, organizations can create AI tools that excel at specific tasks while using fewer computational resources.
Domain-specific accuracy and contextual appropriateness
Because the model’s weights are adjusted during fine-tuning, the resulting model can generate responses that are more accurate and contextually appropriate for the domain it’s tuned on. A fine-tuned legal AI doesn’t just know legal terms; it understands when to use “whereas” clauses, how to structure legal arguments, and which precedents typically apply to different situations. Similarly, a medical AI fine-tuned on clinical notes learns not just medical vocabulary but also the concise, specific way doctors document patient encounters. The model tends to use the correct jargon naturally, follow desired formats without explicit prompting, and handle niche questions that would stump a generic model.
Efficiency gains through model optimization
Fine-tuning can make a smaller model perform as well as a much larger one on specific tasks, dramatically reducing computational costs. A striking example comes from a Snorkel AI study, where a fine-tuned model matched the performance of GPT-3 on a task while being 1,400 times smaller in size. This efficiency gain transforms the economics of AI deployment. Instead of running expensive, large models for every query, organizations can deploy lightweight, specialized models that deliver equal or better performance at a fraction of the cost. These smaller models also respond faster and can run on less powerful hardware, making AI accessible in resource-constrained environments.
Customized tone and style control
Fine-tuning allows precise customization of the model’s tone or style, which proves essential for maintaining brand consistency and meeting specific communication needs. A company-specific chatbot can be fine-tuned to follow the organization’s voice guidelines, whether that means being professionally formal for a law firm or warmly conversational for a retail brand. An AI writing assistant for academic researchers learns to adhere to formal language conventions and citation styles, while one for marketing teams adopts persuasive, engaging language. This stylistic control extends to format preferences, response length, and even subtle aspects like humor or empathy levels, ensuring the AI communicates exactly as the organization intends.
Challenges of fine tuning
While fine-tuning can create powerful specialized models, it comes with significant drawbacks and requirements that organizations must carefully consider. These challenges often make fine-tuning impractical for certain use cases, particularly when information changes frequently or when transparency is essential.
Data and computational requirements
Fine-tuning an LLM requires a lot of high-quality, labeled data and computational resources that many organizations struggle to provide. Preparing the dataset can be labor-intensive, involving extensive data collection, cleaning, and labeling processes that might take weeks or months. A healthcare organization fine-tuning a model for medical diagnosis assistance might need thousands of accurately labeled case studies, each verified by medical professionals. The training process itself demands powerful GPUs or TPUs, especially for large models, with costs that can reach tens of thousands of dollars for a single fine-tuning run. Even with parameter-efficient methods, organizations need specialized hardware and expertise that may not be readily available.
Risk of overfitting
There’s a significant risk of the model overfitting or becoming too specialized as it focuses intensely on one domain. A model fine-tuned extensively on legal documents might excel at contract analysis but struggle with basic tasks it previously handled well, like summarizing news articles or answering general questions. This narrowing effect means organizations often need to maintain multiple models for different purposes rather than relying on one versatile assistant. The model might also memorize specific examples from the training data rather than learning general principles, leading to poor performance on cases that differ slightly from the training examples.
Maintenance and knowledge updates
Maintaining a fine-tuned model proves challenging when domain knowledge evolves. If new medical research emerges or laws change, you must update the training data and re-train the model to keep it current. This retraining cycle can take days or weeks and cost thousands of dollars in compute resources, compared to RAG’s approach of simply adding new documents to a database. Organizations in rapidly changing fields might find themselves in a constant cycle of retraining, with models becoming outdated before the next version is ready. The lag between identifying needed updates and deploying a retrained model can leave users working with dangerously outdated information.
Lack of source attribution
Fine-tuning doesn’t inherently provide source attribution for facts, creating transparency and trust issues in high-stakes applications. The model’s answers come from its internal parameters rather than explicit retrieved documents, making it nearly impossible to verify where specific information originated. When a fine-tuned legal AI provides advice, lawyers cannot check which cases or statutes informed that advice. In healthcare, doctors cannot verify which studies or guidelines shaped a recommendation. This opacity makes fine-tuned models unsuitable for applications requiring audit trails, regulatory compliance, or situations where users need to verify the accuracy and currency of information independently.
Example use-case
Fine-tuning’s transformative power becomes clear when examining real-world applications where generic models fall short. Consider a medical question-answering model built to assist healthcare providers. You could fine-tune a general LLM on a dataset of medical cases, symptoms, and diagnoses drawn from thousands of patient records and medical literature. The resulting model will be much more accurate in providing medical advice or diagnostic suggestions than a generic model because it has learned medical terminology and associations. It knows that “EKG” relates to heart issues, understands the typical progression of conditions like pneumonia, and recognizes drug interactions that a general model might miss.
When a doctor asks this fine-tuned model for a differential diagnosis based on a set of symptoms, it responds with relevant, medically sound suggestions using proper terminology. If presented with “42-year-old male with acute onset chest pain, diaphoresis, and elevated troponin levels,” the model immediately recognizes potential acute coronary syndrome and suggests appropriate diagnostic steps and treatments. It formats its response like actual clinical notes, using medical abbreviations correctly and following the systematic approach doctors expect.
This example shows how fine-tuning tailors an LLM to excel in a particular context, transforming a generalist into a specialist. The medical model doesn’t just know medical terms; it thinks like a medical professional. This deep specialization explains why organizations invest significant resources in fine-tuning despite its challenges, particularly in fields where domain expertise can significantly impact outcomes.
Key differences between RAG vs fine tuning
When choosing between RAG and fine-tuning, understanding their fundamental differences helps organizations select the right approach for their specific needs. Each method excels in different scenarios, and neither is universally superior. The following comparison examines how these approaches differ across critical factors that impact implementation decisions.
Data freshness
RAG pulls information from an external data source on the fly, while fine-tuning bakes information into the model’s parameters. This fundamental difference shapes how each approach handles knowledge currency. With RAG, the model’s knowledge can be as fresh as the latest entries in the database, updated to the minute if needed. A fine-tuned model remains limited to what it saw during its last training session.
RAG excels at providing up-to-date information seamlessly. If there’s new data like today’s news or a new company policy, a RAG-based solution can immediately use it to answer questions by retrieving it. A fine-tuned model would not know about that new information until it’s retrained, potentially giving outdated answers for weeks or months. This makes RAG a strong choice for scenarios where information changes frequently or real-time data is required, such as dynamic knowledge bases, breaking news, or stock prices.
Consider asking an AI about a software release from last week or today’s weather. A fine-tuned model, even a highly capable one, won’t have that information if it wasn’t in its training data. A RAG solution can retrieve the latest data and provide a current answer. This contrast clearly shows how each approach deals with knowledge currency, making RAG indispensable for time-sensitive applications.
Implementation complexity
The work involved in implementing RAG versus fine-tuning differs significantly in both nature and timing. RAG requires building an ecosystem around the LLM including a document store or vector database, a retrieval engine with embeddings and similarity search, and the engineering to connect these components. Data engineers must set up pipelines to ingest and update documents while ensuring search efficiency. Once established, however, adding or updating data becomes straightforward.
Fine-tuning requires a machine learning training pipeline with different complexities. Teams need to gather labeled datasets and have infrastructure like GPUs or TPUs to train the model. For very large models, full fine-tuning can be extremely resource-intensive, sometimes taking days of compute time. Even with parameter-efficient fine-tuning techniques that train only part of the model, teams need ML expertise to execute the process correctly, choosing hyperparameters and preventing overfitting.
The cost structures also differ substantially. Fine-tuning has high upfront costs in computation and human effort for data labeling, but once complete, using the model involves standard inference costs. RAG saves on training costs but incurs ongoing expenses in maintaining infrastructure and performing retrieval for each query. There’s also runtime overhead, as RAG performs database lookups before generating answers, which can make responses slightly slower or more complex to scale.
When scaling across multiple domains or clients, the approaches diverge further. Fine-tuning might require multiple model versions, one per domain or client, which becomes expensive to train and maintain. RAG can handle multiple domains by switching data sources while using the same model, a more practical solution many companies have discovered after realizing the impracticality of training separate fine-tuned LLMs for each customer.
Performance
Fine-tuning generally yields very high accuracy on domain-specific tasks because the model has learned the domain inside-out from training data. It produces outputs well-tailored to context, using correct terminology and providing solutions aligned with training examples. A fine-tuned legal model will likely outperform both non-fine-tuned models and RAG approaches on legal question-answering benchmarks.
RAG tends to improve factual accuracy by grounding the LLM’s answers in real data. Since the model receives relevant text from trusted sources, it’s less likely to hallucinate facts, pulling exact phrases or figures from retrieved documents. This makes RAG highly effective at reducing hallucinations about retrievable knowledge. However, RAG’s final answer quality still depends on the base model’s ability to incorporate context, and poor or irrelevant retrieved documents can lead to poor answers.
Fine-tuning often produces more consistent style and output format because the model has been explicitly trained on the desired style. RAG uses a general model that may not be perfectly adapted to the domain, though it provides real references for accuracy. The content might be accurate but the phrasing more generic. Depending on the use case, organizations might prioritize factual accuracy, favoring RAG, or stylistic consistency, favoring fine-tuning.
For complex questions, a fine-tuned model might deliver an answer that’s very on-point and well-structured for that domain, essentially recalling patterns from training. A RAG solution would deliver an answer including current facts or data with possibly less tailored prose. Both aim for correctness through different means—one via knowledge internalization, the other via knowledge lookup.
Scalability
With RAG, updating knowledge is as simple as adding new data to the knowledge base. New documentation or evolving knowledge sources can be ingested into the RAG pipeline through indexing, and the model can immediately use that information for future queries. There’s no need to retrain the model, making maintenance relatively easy and continuous. This suits scenarios where knowledge changes frequently, like product documentation updating weekly or live information databases.
A fine-tuned model remains essentially static after training. Significant new information or domain changes, such as new regulations in law or new product features, leave the model’s knowledge outdated until retraining on an updated dataset. This retraining represents a non-trivial project involving new data collection, fine-tuning, and redeployment. While less flexible in rapidly changing environments, fine-tuned models might be easier to deploy at scale once trained, requiring only model hosting rather than both model and database infrastructure.
If application scope broadens, RAG can scale by incorporating more data sources or documents into the retrieval. A RAG-powered chatbot can expand from finance to finance plus legal by adding a legal knowledge base and query routing, all without changing the model. A fine-tuned model would need new training rounds to handle expanded domains or require maintaining multiple models.
From a long-term perspective, RAG requires ongoing effort in curating and monitoring the knowledge base, ensuring document relevance and search quality. Fine-tuned models require periodic retraining as data evolves, representing bigger but less frequent efforts. Resource availability often determines which approach proves more sustainable.
Security
RAG’s approach keeps sensitive information within secured databases or knowledge repositories. The LLM only sees information at query time without storing it permanently in its weights. This enables easier enforcement of data access controls, requiring user permissions for certain document retrieval. Data never leaves company storage, aiding compliance with regulations like GDPR or HIPAA.
Fine-tuning actually feeds sensitive data into the model during training, creating potential risks if the model might regurgitate training data. Large language models have raised concerns about unintentionally leaking training data verbatim. If asked questions triggering memories of training examples, fine-tuned models might output proprietary text from their training sets. While careful training and filtering can mitigate these risks, they persist. Once data enters the model, removal becomes difficult, whereas RAG allows immediate deletion from the knowledge base.
RAG provides clear separation between model and data. Organizations with highly confidential data might prefer RAG so data never leaves secure storage. Fine-tuning would require trust in the training process and potentially keeping models in secure environments since they contain embedded data. A bank or healthcare provider might choose RAG so customer data and records are fetched securely when needed, rather than fine-tuning a model on that data, demonstrating why industries handling sensitive information often lean toward RAG for compliance and auditability.
When to use Retrieval-Augmented Generation (RAG)?
RAG becomes the optimal choice when your use case demands current information, operates with limited resources, or requires transparent sourcing of answers. The following scenarios highlight where RAG’s unique capabilities provide clear advantages over traditional approaches or fine-tuning.
Rapidly changing or expansive knowledge
RAG excels in projects where information changes frequently or is too broad to feasibly train into a model. Customer support bots that reference continually-updated knowledge bases benefit from RAG’s ability to instantly incorporate new information. Assistants requiring real-time data like stock prices, news, or sports scores need RAG’s dynamic retrieval capabilities. Tools answering questions from huge document repositories can leverage RAG to search through millions of documents without the impossible task of training on all that content.
The ability to pull in the latest or highly specific information makes RAG indispensable for these use cases. A financial advisory tool can provide current market analysis, a legal research assistant can reference yesterday’s court decisions, and a technical documentation system can include this morning’s software updates, all without any model retraining.
Limited training data or resources
Organizations without large labeled datasets or compute resources for fine-tuning can achieve quick wins with RAG. You can stand up a retrieval system over existing text, even unstructured data, without intensive model retraining. If you have extensive internal documents but they’re not formatted as neat question-answer pairs, RAG can still use them to answer questions effectively. Fine-tuning would require converting those documents into training sets of prompt-response pairs, a labor-intensive process many organizations cannot afford.
Small teams can implement RAG using existing documents, wikis, and databases without hiring ML engineers or renting GPU clusters. This accessibility makes RAG particularly attractive for startups, research groups, and departments within larger organizations that need AI capabilities without massive infrastructure investments.
High emphasis on accuracy and traceability
When citing sources or quickly updating incorrect information is crucial, RAG often becomes the preferred choice. Many enterprises favor RAG because of its scalability, security, and reliability in delivering accurate answers. The ability to trace answers back to specific documents and update data quickly means less risk when information changes or errors are discovered.
Consider building an AI assistant for an e-commerce platform’s help center with tons of product information and policy documents. Using RAG, the assistant can retrieve exact product manual snippets or return policy paragraphs to answer customer questions. It always gives answers based on current, approved information, and any policy changes are immediately reflected by updating the documents. No retraining needed. This traceability also helps with compliance and audit requirements, as every answer can be linked to its authoritative source.
When to use fine tuning?
Fine-tuning becomes the superior choice when your application demands specialized expertise, consistent output formats, or operates under deployment constraints that prevent external data access. The following scenarios demonstrate where fine-tuning’s ability to embed knowledge directly into model parameters provides distinct advantages over retrieval-based approaches.
Highly specialized tasks or formats
Fine-tuning shines for applications where output needs to follow specific formats or where the domain requires specialized vocabulary. Drafting legal contracts, writing medical reports, or generating code in specific programming languages benefit from fine-tuning because the model learns exact structures, terminology, and nuances required. When maximizing performance on narrowly defined tasks is the goal, fine-tuning’s ability to deeply specialize becomes invaluable.
A model fine-tuned on thousands of radiology reports learns not just medical terminology but also the precise formatting radiologists expect, the standard phrases for describing findings, and the systematic approach to documenting observations. This level of specialization goes beyond what RAG can achieve through retrieval alone.
Improving a base model’s weakness
If the base LLM performs poorly on certain queries or exhibits biases and repetitive errors, fine-tuning on focused datasets can correct these issues. When companies have thousands of past customer interactions and want a chatbot responding in a very on-brand manner, fine-tuning the model on those interactions with the best responses labeled can imbue the model with that specific style and knowledge.
Fine-tuning also helps when the base model lacks familiarity with domain-specific concepts. A general model might not recognize specialized manufacturing terminology or industry-specific acronyms. Fine-tuning on domain data teaches these concepts at a fundamental level, improving the model’s ability to reason about domain-specific problems.
It has been established that for many use cases, a fine-tuned small model can outperform a large general purpose model – making fine tuning a plausible path for cost efficiency in certain cases.
For example, Snorkel AI created a data-centric foundation model to bridge the gaps between their foundation models and enterprise AI. Their Snorkel Flow capabilities include fine-tuning, along with a prompt builder and “warm start,” to give data science and machine learning teams the tools they need to effectively put foundation models to use for performance critical enterprise use cases.
This resulted in the Snorkel Flow and Data-Centric Foundation Model Development achieving the same quality as a fine-tuned GPT-3 model with a deployment model that was 1,400x smaller, required <1% as many ground truth (GT) labels, and costs 0.1% as much to run in production.
Resource trade-offs and deployment constraints
Fine-tuning becomes the natural choice when real-time retrieval isn’t necessary or possible. Deployment environments that are offline or on-device, where hosting large external databases isn’t feasible, benefit from having all knowledge embedded in the model. Mobile applications, embedded systems, or secure environments without internet access require self-contained models that fine-tuning provides.
Organizations with existing annotated datasets and ML pipelines often find fine-tuning aligns with their capabilities. It can also prove cost-effective for high-volume tasks. Once you fine-tune a smaller model to perform like a larger one, you can serve many requests cheaply. The Snorkel AI study demonstrated a fine-tuned small model outperforming a larger one at a fraction of the running cost, making fine-tuning attractive for applications with millions of daily queries.
Imagine a company needing AI to generate quarterly financial reports from raw data. A fine-tuned model trained on past reports and data learns the precise report structure and tone the company uses. When given new quarter figures, it drafts reports in the company’s style automatically. This case demands format and style consistency, something fine-tuning excels at since the model internalizes exactly how to structure and present information according to company standards.
When to combine RAG and fine tuning (hybrid approach)
The most sophisticated AI applications often benefit from combining both RAG and fine-tuning to create solutions that exceed what either approach can achieve alone. This hybrid strategy allows organizations to leverage fine-tuning’s deep domain expertise alongside RAG’s dynamic information retrieval, resulting in AI that performs expertly while staying current.
Not mutually exclusive
RAG and fine-tuning are not an either/or choice in every case. They can be combined for additive benefits that leverage the strengths of both approaches. An organization might fine-tune a model on domain-specific data and use RAG to feed it the latest facts. This way, the model has both a deep specialization in the domain and the ability to pull in fresh, specific information as needed.
This hybrid approach creates AI systems that excel at both specialized reasoning and current information retrieval. The fine-tuned component provides domain expertise, proper terminology usage, and appropriate output formatting, while the RAG component ensures access to the most recent data, documents, and developments in the field.
Use case for hybrid
Consider a legal document analysis AI that combines both approaches effectively. You could fine-tune an LLM on a corpus of legal documents to teach it legal language and reasoning, then use RAG to provide it with the most up-to-date laws or case files when answering questions. The fine-tuned model generates analysis in a lawyerly tone and structure, using proper legal terminology and following standard legal reasoning patterns. Meanwhile, RAG ensures it cites the latest relevant legislation or case precedents that the model wouldn’t otherwise know.
This combination proves particularly powerful in professional domains where both expertise and currency matter. A medical diagnosis assistant might use fine-tuning to learn diagnostic reasoning and medical terminology, while RAG provides access to the latest research papers and treatment guidelines. A financial analysis tool could combine fine-tuning for financial modeling expertise with RAG for current market data and regulatory updates.
Cost/complexity note
Using both approaches means inheriting the complexity of both systems. Organizations need expertise in training models and building retrieval systems, along with the infrastructure to support both components. This approach might only make sense for very high-stakes requirements or organizations with ample resources.
However, the hybrid approach can deliver excellent results in practice. Some organizations find that fine-tuning the model moderately and using RAG for anything not covered in training provides an optimal balance. This strategy allows them to avoid extensive fine-tuning while still achieving domain specialization, then relying on RAG to fill knowledge gaps and provide current information.
Guidance
Consider your project’s priorities when deciding between approaches. Is real-time knowledge more important, or is task-specific skill more important? How often does your data change? Do you have the data to fine-tune? What are your resource constraints and technical capabilities?
By weighing these factors, you can make an informed decision. Many organizations start with one approach and later incorporate the other as their needs evolve. A common pattern involves beginning with RAG for quick deployment and adding fine-tuning once they’ve collected enough domain-specific training data. Others start with fine-tuning for core capabilities and add RAG when they need to incorporate frequently changing information.
The key is recognizing that these technologies complement rather than compete with each other. Your choice doesn’t lock you into a single path. As your application matures and requirements become clearer, you can adapt your approach to achieve the best results for your specific use case.
Choosing between RAG, fine-tuning, or a hybrid approach for AI
Making the right choice between RAG, fine-tuning, or a hybrid approach requires evaluating several key factors against your specific requirements and constraints. Each factor plays a crucial role in determining which approach will deliver the best results for your organization.
Cost/budget considerations extend beyond initial implementation. RAG typically requires lower upfront investment but ongoing costs for database hosting and retrieval infrastructure. Fine-tuning demands significant initial compute resources for training but results in lower serving costs per query. Hybrid approaches multiply both cost types.
Frequency of domain changes strongly influences the decision. If your information updates daily or weekly, RAG provides clear advantages. For stable domains that change yearly or less frequently, fine-tuning offers better performance without the overhead of constant retrieval.
Data privacy requirements may dictate your choice. Fine-tuning embeds data directly into model weights, which some organizations find concerning for sensitive information. RAG keeps data separate in controlled databases, allowing for easier access management and data deletion when needed.
Engineering resources determine feasibility. RAG implementation requires database and retrieval expertise but uses existing models. Fine-tuning demands ML engineering skills, GPU access, and experience with training pipelines. Hybrid approaches need both skill sets.
Desired level of model control affects your approach. Fine-tuning offers complete control over model behavior and output style. RAG provides less direct control but easier updates and corrections. Consider whether you need precise output formatting or just accurate information delivery.
Start by mapping these factors to your specific use case and constraints. Many successful implementations begin with the simpler approach that meets immediate needs, then expand as requirements become clearer. Remember that your initial choice doesn’t lock you in; the best solution often emerges through experimentation and iteration based on real-world performance.
Final thoughts on RAG vs fine tuning
The choice between RAG and fine-tuning represents more than a technical decision; it shapes how your AI applications will perform, scale, and adapt over time. RAG excels when you need current information, have limited training resources, or require transparent sourcing. Fine-tuning shines for specialized tasks requiring consistent formatting, domain expertise, or offline deployment. The hybrid approach combines both strengths for applications demanding both expertise and currency.
Your decision should align with your organization’s specific needs and constraints. Consider your budget, how frequently your data changes, privacy requirements, available engineering resources, and the level of control you need over model outputs. Start with the approach that addresses your immediate requirements, knowing you can adapt your strategy as your needs become clearer through real-world usage.
Success with either approach depends not just on the initial implementation but on maintaining high-quality data throughout the process. Poor data quality undermines both RAG and fine-tuning: irrelevant or outdated documents degrade RAG performance, while mislabeled or biased training data produces unreliable fine-tuned models. These data quality issues can silently erode AI performance, leading to hallucinations, outdated responses, or biased outputs that damage user trust.
This is where data observability tools like Monte Carlo become essential. They help organizations monitor data quality, detect anomalies, and ensure data freshness across their AI pipelines. For RAG implementations, Monte Carlo can alert teams when document databases contain stale information or when retrieval patterns indicate potential issues. For fine-tuning projects, it can validate training data quality and flag potential biases or gaps before they impact model performance.
To see how Monte Carlo can not just detect but help teams identify the root cause of incidents check out the video below on our Troubleshooting Agent:
By providing visibility into data health and lineage, these tools help teams build more reliable AI applications and maintain them effectively over time. Data observability transforms data quality from a hidden risk into a managed asset, ensuring your AI investments deliver consistent value whether you choose RAG, fine-tuning, or a combination of both approaches.
To learn more about how data observability can ensure the reliability of your GenAI pipelines, chat with our team here.
Our promise: we will show you the product.
Frequently Asked Questions
Is rag better than fine-tuning?
RAG is generally better for most enterprise use cases because it is more secure, scalable, and cost-efficient. It allows for enhanced security and data privacy, reduces compute resource costs, and provides trustworthy results by pulling from the latest curated datasets.
What is the difference between rag and fine-tuning vs prompt engineering?
RAG involves augmenting an LLM with access to a dynamic, curated database to improve outputs, while fine-tuning involves training an LLM on a smaller, specialized dataset to adjust its parameters for specific tasks. Prompt engineering involves crafting queries to elicit better responses from the model without altering the model or its data sources.
Can rag and fine-tuning be used together?
Yes, RAG and fine-tuning can be used together. While fine-tuning trains the model to better understand specific tasks, RAG ensures the model has access to the most relevant and up-to-date data. Combining both methods can enhance the performance and reliability of the model.
Is rag cheaper than fine-tuning?
RAG is generally more cost-efficient than fine-tuning because it limits resource costs by leveraging existing data and eliminating the need for extensive training stages. Fine-tuning requires significant time and compute power for training the model with new data, making it more resource-intensive.
When to use rag vs fine-tuning?
Use RAG when you need a scalable, secure, and cost-efficient solution for integrating up-to-date and reliable information into LLM outputs. Use fine-tuning when you need the model to perform better on specific tasks by training it on a specialized dataset.
What is the difference between rag, fine-tuning, and embedding?
RAG (Retrieval-Augmented Generation) connects an LLM to a curated database to improve outputs by integrating reliable information. Fine-tuning adjusts the model’s parameters by training it on a specialized dataset to improve performance on specific tasks. Embedding involves representing data in a lower-dimensional space to capture semantic relationships, used to enhance the model’s understanding of context and meaning.





