Machine Learning Observability: The Complete Guide to Monitoring Models in Production

Table of Contents
One duplicate data set or stale model can cause unintended (but severe) consequences that monitoring alone can’t catch or prevent. The solution? Observability. Here’s how it differs from traditional monitoring and why it’s necessary for building more trustworthy and reliable data products.
Garbage in, garbage out. It’s a common saying among data and ML teams for good reason—but in 2021, it’s no longer sufficient.
Data (and the models it powers) can break at any point in the pipeline, and it’s not enough to simply account for data quality issues at ingestion. Similarly, when you’re deploying ML models, a myriad of issues can arise that weren’t seen during testing or validation, not just with the data itself.
And when you don’t know that something broke in your environment – let alone how it happened – it compromises the integrity of your analytics and experiments, not to mention the trust of your stakeholders.
For businesses, this can mean a loss of revenue, wasted resources, and ill-informed decision-making. In real-world applications, the consequences of ML models powered by bad data can be even more consequential. For example, in 2020, a Black man in Detroit was wrongfully arrested and jailed after being misidentified by facial-recognition software, likely due to bias issues that include training datasets that are predominately white and male.
And the problem of bad data in ML is undeniably widespread. MIT recently took down their entire 80 Million Tiny Images dataset due to racist, sexist, and offensive labels, and the massive ImageNet library removed over 600,000 images after the online art project ImageNet Roulette revealed similar problems. These datasets have been used to train ML models for years—deeply flawed labels and all.
Data quality issues are common because they’re difficult to solve. Maintaining clean, quality data at the scale needed for most data and ML projects is incredibly time-consuming—and without the right approach, near to impossible. Here’s where observability comes in.
Defining data observability
An easy way to frame the effect of “garbage data” (no matter where it lives in your system) is through the lens of software application reliability. For the past decade or so, software engineers have leveraged targeted solutions like New Relic and DataDog to ensure high application uptime (in other words, working, performant software) while keeping downtime (outages and laggy software) to a minimum.
In data, we call this phenomena data downtime. Data downtime refers to periods of time when data is partial, erroneous, missing, or otherwise inaccurate, and it only multiplies as data systems become increasingly complex, supporting an endless ecosystem of sources and consumers.
By applying the same principles of software application observability and reliability to data and ML, these issues can be identified, resolved and even prevented, giving data teams confidence in their data to deliver valuable insights.
What is machine learning observability?
Machine learning observability is the practice of closely monitoring and understanding how ML models perform in real-world production environments. It’s about having a window into your model’s internal state and behavior, not just knowing whether it’s running or has crashed. When teams implement ML observability, they track critical metrics, indicators, and processes to ensure their models are working as expected once deployed. Think of it as giving yourself X-ray vision into how your model thinks and makes decisions in the wild.
The concept becomes clearer when you compare it to traditional software observability. Just as DevOps teams use observability to understand web app health by tracking logs, metrics, and traces, ML teams use observability to understand model health. But there’s an important difference. Unlike a static program that behaves predictably, a machine learning model’s performance can change over time because the data it processes constantly evolves. Customer behaviors shift, market conditions fluctuate, and seasonal patterns emerge. This dynamic nature means that observability in machine learning requires continuous attention. What worked perfectly last month might struggle today, not because the model broke, but because the world it’s trying to understand has changed.
This is where ML observability truly shines, as it offers much more than basic monitoring. While simple monitoring might alert you that your model’s accuracy has dropped, model observability helps engineers understand why that drop occurred. Maybe the input data has shifted in unexpected ways, or perhaps certain types of predictions are failing while others remain accurate. By providing these deeper insights into model behavior, observability transforms vague problems into specific, solvable challenges. It’s the difference between knowing something is wrong and understanding exactly what needs to be fixed, setting the stage for more sophisticated approaches to maintaining AI models in production.
Key benefits of machine learning observability
Without ML observability, teams are essentially flying blind with models in production. Imagine deploying a recommendation algorithm for millions of users without knowing if it’s actually working correctly. Problems like model performance degradation or crashes can go unnoticed for days or even weeks until customers start complaining or revenue drops. By then, the damage is already done. This is why ML observability matters so much in today’s data-driven world.
Early detection of issues
With proper observability, data scientists can get alerted the moment model metrics deviate from normal patterns. This means catching accuracy drops, latency spikes, or unusual prediction patterns before they spiral into bigger problems. For instance, if your fraud detection model suddenly starts flagging legitimate transactions at twice the usual rate, observability tools can alert you within minutes rather than after hundreds of frustrated customers call your support line. This early warning capability prevents prolonged bad predictions and costly downtime.
Root cause analysis
Here’s where observability really proves its worth. It doesn’t just tell you that something went wrong; it helps you understand why. If your model’s accuracy is dropping, observability can reveal whether it’s due to specific data drift, a bug in the data pipeline, or perhaps a change in user behavior. Maybe your e-commerce recommendation model started performing poorly because a new product category was added that it wasn’t trained on. This ability to pinpoint root causes transforms troubleshooting from frustrating guesswork into systematic problem-solving, often reducing fix times from days to hours.
Maintaining model performance and trust
The real world doesn’t stand still, and neither should your models. User behaviors shift, new trends emerge, and what worked last quarter might fail today. This phenomenon, known as data drift, is one of the biggest challenges in machine learning. Observability helps detect this drift before accuracy suffers. Consider a credit scoring model trained before a major economic shift. Without observability, it might continue making outdated predictions based on pre-recession patterns, potentially denying loans to qualified applicants or approving risky ones. By monitoring for these changes and triggering retraining when needed, teams maintain both model accuracy and user trust.
Regulatory and compliance needs
For industries like healthcare and finance, observability provides the audit trails and explainability required for compliance. When a loan application is rejected or a medical diagnosis is suggested, regulators often require explanations for these decisions. Observability tools capture the data, model versions, and decision logic used for each prediction, creating a clear paper trail. This transparency helps organizations meet regulations like GDPR’s “right to explanation” and supports ethical AI practices by making model decisions interpretable and accountable.
Efficient use of resources
Observability monitors more than just accuracy. It also tracks resource utilization like CPU usage, memory consumption, and inference time. This ensures models run efficiently in production and alerts teams if response times suddenly slow down. A computer vision model that usually processes images in 100 milliseconds but suddenly takes 500 milliseconds might indicate a memory leak or need for infrastructure scaling. For DevOps teams managing costs and reliability, these insights are invaluable for keeping models running smoothly without breaking the budget.
The consequences of ignoring observability can be severe. In 2016, Microsoft’s chatbot Tay famously turned offensive within hours of deployment because the team lacked proper monitoring of its learning patterns. More recently, numerous companies have faced backlash when biased models made unfair decisions about hiring, lending, or healthcare access. These failures often could have been prevented with proper observability practices. Whether it’s lost revenue, damaged reputation, or regulatory fines, the costs of flying blind far exceed the investment in proper model observability. That’s why forward-thinking organizations now consider observability not as an optional extra, but as a fundamental requirement for any ML deployment.
Data monitoring vs. data observability
One question that comes up a lot is: “I already monitor my data. Why do I need observability, too?”
It’s a good question. For so long, the two have been used interchangeably, but monitoring and observability are two very different things.
Data observability enables monitoring, which is familiar to most technical practitioners: we want to be the first to know when something breaks, and to troubleshoot quickly. Data quality monitoring works in a similar way, alerting teams when a data asset looks different than the established metrics or parameters say it should.
For example, data monitoring would issue an alert if a value falls outside an expected range, data hasn’t updated as expected, or 100 million rows suddenly turn into 1 million. But before you can set up monitoring for a data ecosystem, you need visibility into all of those attributes we’ve just discussed—here’s where data observability comes in.
Data observability also enables active learning by providing granular, in-context information about data. Teams can explore data assets, review schema changes, and identify root causes to new or unknown problems. By contrast, monitoring issues alerts based on pre-defined problems, representing data in aggregates and averages.
With data observability, companies gain insight into five key pillars of data health: freshness, distribution, volume, schema, and lineage. For machine learning practitioners, observability helps provide a level of confidence that the data feeding your models is complete and up-to-date, and falls within accepted ranges.

And when problems do arise, visibility into schema and lineage helps swiftly answer pertinent questions about what data was impacted; what changes may have been made, when, and by whom; and which downstream consumers may be impacted.
Observability incorporates monitoring across the five pillars of data health, but also alerting and triaging of issues and end-to-end, automated data lineage. Applied together, these functionalities are what make data observability a must-have for the modern data stack.
One null value spoils the dashboard
It’s one thing to know that your data pipeline broke. But how can you actually figure out what happened and why?
Unlike monitoring, data observability can be used to handle root cause analysis when data pipelines break. In theory, root causing sounds as easy as running a few SQL queries to segment your data, but in practice, this process can be quite challenging. Incidents can manifest in non-obvious ways across an entire pipeline and impact multiple, sometimes hundreds, of tables.
For instance, one common cause of data downtime is freshness – i.e. when data is unusually out-of-date. Such an incident can be a result of any number of causes, including a job stuck in a queue, a time out, a partner that did not deliver its dataset timely, an error, or an accidental scheduling change that removed jobs from your DAG.
By taking a historical snapshot of your data assets, data observability gives you the approach necessary to identify the “why?” behind broken data pipelines, even if the issue itself isn’t related to the data itself. Moreover, the lineage afforded by many data observability solutions gives cross-functional teams (i.e., data engineers, data analysts, analytics engineers, data scientists, etc.) the ability to collaborate to resolve data issues before they become a bigger problem for the business.
Machine learning observability vs. data monitoring
Many people use the terms “ML monitoring” and “ML observability” interchangeably, but they’re actually quite different. Monitoring is about tracking metrics and raising alerts when something goes wrong. It tells you what happened. Observability, on the other hand, goes deeper to provide context and answers about why it happened. Think of it this way. Monitoring might tell you a model’s accuracy dropped below 80%, but observability helps you discover whether it was due to a specific data shift, a new user segment, or a pipeline error. One gives you the symptom, the other helps you diagnose the disease.
The scope of these two approaches also differs significantly. Monitoring is typically a subset of observability, dealing with predefined metrics like accuracy, latency, and throughput. You set thresholds, and when they’re crossed, you get an alert. Observability has a broader scope that encompasses the model, the data, and the entire surrounding infrastructure. It requires correlating information from multiple sources such as model metrics, data quality indicators, application logs, and infrastructure performance. This comprehensive view is what allows teams to truly understand their ML system’s behavior rather than just track its vital signs.
Perhaps the biggest difference lies in their fundamental purpose. Monitoring is mainly reactive. It triggers alerts when issues arise, letting you know that something needs attention. Observability is proactive, enabling debugging and continuous improvement. It’s built for troubleshooting, helping you investigate root causes rather than just acknowledging that a failure occurred. A helpful analogy is to think of monitoring as checking your car’s dashboard lights. They’ll tell you when something’s wrong. Observability is like opening the hood and inspecting the engine to understand exactly what’s causing that check engine light to flash.
Both monitoring and observability serve important roles in maintaining healthy ML models. They work hand in hand rather than competing with each other. Monitoring acts as your early warning system, alerting you to problems that need attention. Observability then provides the tools and insights you need to solve those problems effectively. This is why organizations serious about their machine learning deployments shouldn’t settle for just basic monitoring. They need comprehensive observability to monitor model performance effectively and maintain reliable AI applications. Without this deeper level of insight, teams end up playing whack-a-mole with model issues, fixing symptoms without addressing underlying causes.
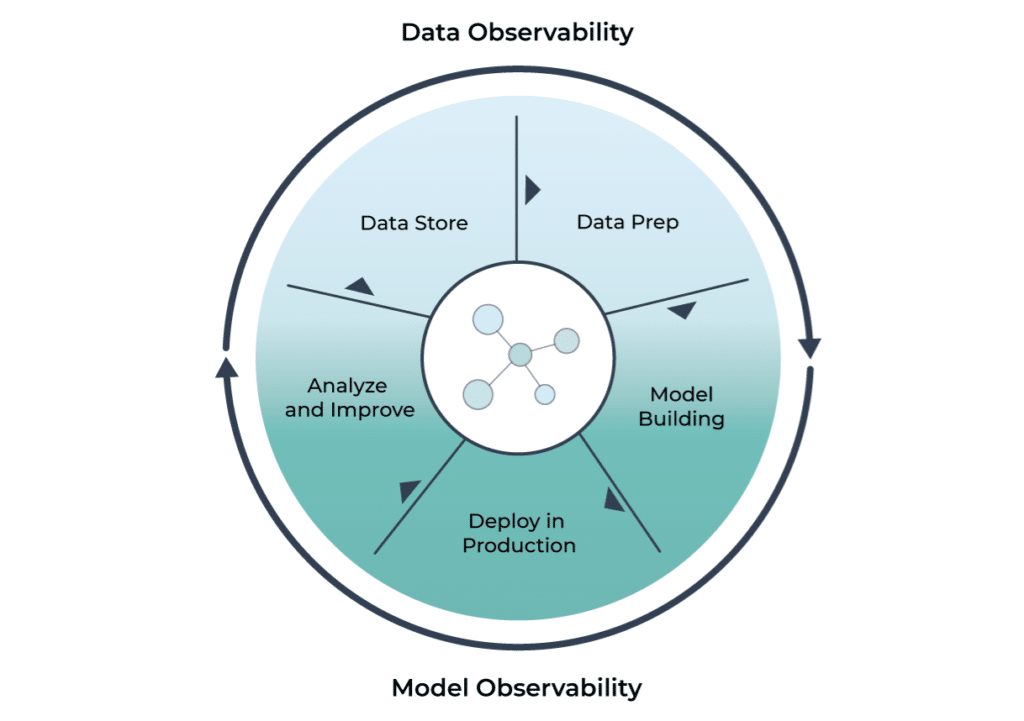
Machine learning observability vs. data observability
Before diving into the differences, let’s clarify what data observability means. Data observability is the practice of monitoring the health and quality of data pipelines, ensuring that data moving through your ETL processes or data warehouse is accurate, complete, and fresh. It’s about catching broken data, schema changes, or pipeline failures before they cascade into bigger problems downstream. If your sales data suddenly stops updating or customer records start showing up with missing fields, data observability helps you catch and fix these issues quickly.
While data observability focuses on the reliability of data pipelines, ML observability zeroes in on models and their behavior. Here’s how they differ:
Focus:
- Data observability: Data pipelines and data quality
- ML observability: Deployed models and their predictions
Key metrics:
- Data observability: Data freshness, completeness, schema consistency (“Did yesterday’s data load fully, or are there missing values?”)
- ML observability: Model accuracy, prediction distributions, drift metrics, inference latency
Primary users:
- Data observability: Data engineers and analysts who need to trust their data
- ML observability: ML engineers and data scientists who need to trust their models’ performance
Common Issues:
- Data observability: Broken pipelines, corrupt data, unexpected schema changes
- ML observability: Performance degradation, predictions going out of expected bounds, model bias
Despite these differences, data observability and ML observability are deeply interconnected. Poor data quality, which data observability would catch, often leads directly to model issues that ML observability needs to address. If your customer data suddenly has formatting errors, your recommendation model will likely start making strange predictions. In practice, teams need both to reliably run machine learning in production. Data observability ensures your data is trustworthy; ML observability ensures your model’s results are trustworthy. They’re two sides of the same coin.
This interconnection has led to an evolution in observability platforms. Companies like Monte Carlo, originally known for data observability, have expanded to track ML model performance metrics as well. They’ve recognized that monitoring data quality without considering its impact on models leaves a critical gap. Similarly, ML-focused platforms are adding data quality checks. This convergence reflects how intertwined these needs have become in modern data stacks. Platforms that combine data observability with ML observability help teams spot issues faster, whether the root cause is bad data or a misbehaving model.
The key takeaway is that successful ML deployments require visibility into both your data and your models. Trying to maintain model health without understanding data quality is like trying to maintain a car while ignoring the quality of the fuel you’re putting in it. Both forms of observability work together to create a complete picture of your machine learning pipeline’s health.
Key components of ML observability
ML observability involves several interconnected components or pillars that work together to provide complete visibility into your models. These are the essential vital signs you need to monitor to keep your models healthy and performing well. Each component addresses a different aspect of model health, and together they create a comprehensive view of what’s happening inside your machine learning applications.
Monitoring model performance metrics
The foundation of ML observability is tracking both prediction quality and operational efficiency. This includes accuracy, precision, recall, and F1-scores alongside infrastructure metrics like latency, throughput, and resource usage. Observability platforms establish baseline expectations from training data and continuously compare current performance against these benchmarks to detect regressions. Without ongoing performance monitoring, gradual declines in model quality can go unnoticed until users experience significant problems, making continuous tracking essential for maintaining reliable ML applications.
Data & feature drift detection
Data drift and concept drift occur when input data patterns or the relationships between inputs and outputs change over time, often causing model performance degradation. ML observability monitors input and output distributions against training baselines, automatically flagging when features like average transaction values or class proportions shift significantly. For example, a fraud detection model trained on pre-inflation data might start flagging normal purchases as suspicious when prices increase across the board. Advanced tools can pinpoint exactly which features have drifted most, making it easier to diagnose why model performance has changed.
Input data quality monitoring
Even the best models fail when fed corrupted, incomplete, or improperly formatted data. ML observability incorporates real-time data validation to catch issues like missing values, schema changes, or upstream pipeline failures before they impact predictions. For instance, if a temperature sensor starts sending readings in the wrong units or a data pipeline begins dropping important fields, quality monitoring triggers alerts immediately. This proactive approach prevents small data problems from cascading into major prediction errors or model crashes.
Model explainability & logging
True observability requires understanding why models make specific predictions, not just tracking what they predict. Modern platforms integrate explainability techniques like SHAP values to reveal which features most influence decisions, while comprehensive logging captures prediction details, model versions, and confidence scores for debugging. This combination enables teams to trace any prediction back to its root causes, whether investigating unexpected model behavior or responding to regulatory inquiries about specific decisions. The result is a complete audit trail that supports both technical troubleshooting and compliance requirements in regulated industries.
Best practices to follow when implementing machine learning observability
Implementing ML observability requires a strategic approach that spans from initial model development through production deployment and ongoing maintenance. These best practices will help you incorporate observability into your ML workflow systematically, ensuring you catch issues early and maintain model reliability. From design to deployment, planning for observability at each stage will save countless hours of debugging and prevent costly production failures.
Plan during development
Observability isn’t an afterthought to add once models are in production. During training, data scientists should record baseline metrics on validation sets to establish reference points for production performance. Determine which metrics and data characteristics will be most critical to monitor once the model goes live, such as accuracy on key customer segments or the distribution of prediction outputs. Setting these baselines and KPIs early creates clear benchmarks for detecting when something goes wrong in production.
Instrument your model & pipeline
Production environments need proper instrumentation to enable observability. Add code to log predictions, actual outcomes, and key metadata like model version and timestamp for every inference. Many cloud ML services like AWS SageMaker, Google Vertex AI, and Azure ML offer built-in monitoring features that can jumpstart your observability efforts. For custom deployments, integrate with monitoring tools like Prometheus and Grafana or specialized ML observability platforms to capture and visualize these metrics systematically.
Monitor data as well as model
Implementing ML observability means tracking both your model’s performance and the quality of incoming data. Set up automated data validation tests to catch schema changes, missing values, or statistical shifts before they impact predictions. Consider using data observability tools in tandem with model monitoring to create a complete picture of your ML pipeline health. This dual approach helps distinguish between model issues and data problems, speeding up root cause analysis when performance degrades.
Alerts and dashboards
Configure automated alerts on critical metrics to catch problems before users notice them. Set thresholds for scenarios like error rates doubling, prediction distributions shifting significantly, or key features drifting beyond acceptable ranges. Create intuitive dashboards that visualize model health trends over time, making it easy for teams to spot gradual degradations or sudden changes. Good visualization transforms raw metrics into actionable insights that both technical and business stakeholders can understand and act upon.
Use existing tools and frameworks
Don’t reinvent the wheel when implementing observability. Open-source libraries like Evidently and WhyLogs provide templates for monitoring common ML metrics and detecting drift. Teams often start with these basic tools or custom monitoring solutions, but as deployments scale, dedicated ML observability platforms offer more advanced capabilities. Consider leveraging platforms like Monte Carlo that can monitor data pipelines and model performance together, providing end-to-end coverage without building everything from scratch.
Team process
Implementing observability requires more than just technical tools; it demands cultural and process changes. Establish regular reviews of model performance reports, create clear escalation procedures for alerts, and define retraining triggers based on drift detection. Involve both data engineering and ML engineering teams in incident response, ensuring everyone understands their role when issues arise. Integrate ML observability into your MLOps lifecycle just as logging and monitoring are fundamental parts of DevOps practices.
Emphasize iteration
ML observability implementation is an iterative journey, not a one-time setup. Start by monitoring core metrics like accuracy and latency, then expand coverage based on real incidents and near-misses. When unexpected failures occur that your current monitoring missed, add new metrics or validation checks to catch similar issues in the future. This continuous refinement approach ensures your observability practice evolves alongside your models and catches increasingly subtle issues over time.
Most common machine learning challenges
While implementing ML observability brings tremendous benefits, it’s important to acknowledge the real difficulties teams face along the way. These challenges stem from the inherent complexity of machine learning systems and the environments they operate in. Understanding these obstacles helps set realistic expectations and guides teams toward practical solutions. If you’re struggling with ML observability implementation, you’re not alone. Even the most experienced teams grapple with these issues.
Model complexity
Modern ML models have grown increasingly sophisticated, making them harder to observe and explain effectively. It’s straightforward to monitor a simple linear regression model with a handful of features, but tracking a deep neural network with millions of parameters or an ensemble of 100 gradient-boosted trees presents entirely different challenges. As models evolve toward massive language models and complex computer vision systems, identifying which signals to monitor becomes daunting. Teams often address this by focusing on high-level metrics and using techniques like attention visualization or layer-wise relevance propagation, though these solutions only partially solve the interpretability puzzle.
Scalability
Production ML systems often handle hundreds of models making billions of predictions daily, creating massive observability challenges. Logging every prediction, monitoring all features, and tracking drift across this volume can overwhelm storage systems and create performance bottlenecks. Teams must architect observability pipelines that can handle this scale without impacting model serving latency. Additionally, alert fatigue becomes a real problem when monitoring at scale. Too many false positives lead teams to ignore important warnings. Solutions include implementing sampling strategies, using streaming analytics for real-time processing, and carefully tuning alert thresholds based on business impact rather than statistical significance alone.
Data privacy & security
Monitoring and logging model inputs and outputs can directly conflict with privacy regulations and security requirements. Storing detailed prediction logs might inadvertently capture personally identifiable information (PII), creating compliance risks under GDPR, CCPA, or industry-specific regulations. Healthcare models processing patient data or financial models handling transaction details face particularly strict constraints. Teams tackle this through techniques like differential privacy, aggregated monitoring that tracks patterns without individual records, and careful data retention policies. Some organizations implement separate observability infrastructure for sensitive models, using encryption and access controls to maintain security while still enabling debugging capabilities.
Interpretability
Certain model architectures resist meaningful interpretation by design, making observability particularly challenging. Deep learning models for computer vision or natural language processing operate as black boxes where individual neurons don’t map cleanly to understandable concepts. While techniques like SHAP values and LIME provide some insights, they often fall short of truly explaining why a complex model made specific predictions. The field continues advancing with research into inherently interpretable models and better post-hoc explanation methods, but teams must accept that perfect interpretability remains elusive. Current approaches focus on building trust through consistent performance monitoring and testing edge cases, even when complete model transparency isn’t achievable.
Find the needle in the haystack
So how does ML observability work? Let’s take an example: Your model that predicts if a transaction is fraud goes off the rails and starts to have more false positives. How do we get to the bottom of why?
Being able to automatically surface up cohorts where the performance is low is critical to track down why the model performs better or worse for a particular subset of your data. ML observability helps you narrow down whether there are significantly more false positives occurring in a certain geographic region, a particular segment of customers, or a particular time window.
One common cause of performance degradation is drift. Because models are trained on data, they perform well when the data is similar to what they’ve already seen. Observability compares distribution changes between a baseline distribution and a current distribution. Model owners can do targeted upsampling when there is drift.
In theory, root-causing sounds easy in a Jupyter Notebook, but in practice you have to scale this to 100’s of features, models and model versions across billions of predictions, with automated setup and instant analysis.
We’re excited to see how the next generation of data and ML leaders approach this problem to make answering this question — and many others — much easier.
Interested in learning more? Reach out to Barr or Aparna or book a time to speak with us using the form below.
Our promise: we will show you the product.




