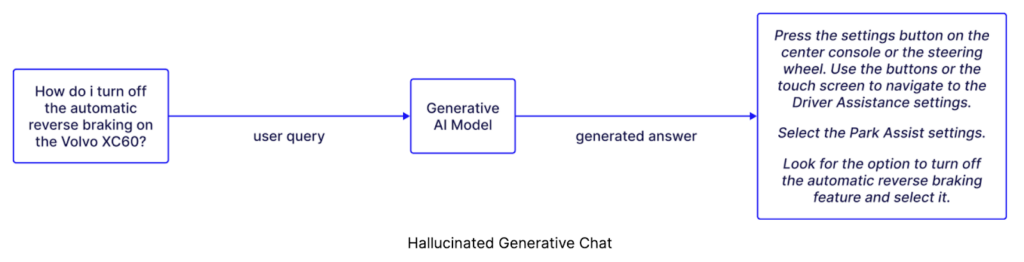
Will AI Replace Data Engineers? No — And Here’s Why.

Table of Contents
The speed of change is unprecedented. AI tools now write production-ready SQL in seconds, debug complex pipelines, and automatically document data flows. Tasks that once took hours now take minutes. Junior engineers watch AI complete assignments faster than they can type. Senior engineers see AI handling work they spent years mastering.
This rapid automation raises an existential question for the profession. If AI can write code, optimize queries, and maintain pipelines, what happens to the humans who currently do this work?
The answer requires understanding what data engineers actually do. They build the infrastructure that transforms raw data into business value. They ensure millions of records flow accurately from source to destination. They maintain quality standards that prevent costly errors. They translate messy business requirements into reliable technical solutions.Here’s the paradox that most discussions miss. Every AI model requires vast amounts of clean, well-structured data. Every automated pipeline needs human oversight. Every business decision based on AI outputs depends on data quality and data accuracy that only engineers can ensure. The same AI revolution that threatens to automate our jobs also multiplies the demand for our expertise.
AI is beginning to upend the way data teams think about ingesting, transforming, and surfacing data to consumers. Tasks that were once fundamental to data engineering are now being accomplished by AI — usually faster, and sometimes with a higher degree of accuracy. For example, check out how the Troubleshooting Agent automatically identifies the root cause of data quality issues in the video below:
As familiar workflows evolve, it naturally begs a question: will AI replace data engineers?
While I can’t in good conscience say ‘not in a million years’ (I’ve seen enough sci-fi movies to know better), I can say with a pretty high degree of confidence “I don’t think so.”
At least, not anytime soon.
Here’s why.
Table of Contents
What AI is reshaping in data engineering
AI in data engineering has moved from experimental to essential. Walk into any data engineering team today and you’ll find AI tools running alongside traditional development environments. From code generation to pipeline monitoring, these tools have quietly integrated into the standard engineering workflow.
Code generation
Data engineers increasingly rely on AI assistants for writing standard code. GitHub Copilot suggests entire functions after reading a single comment. ChatGPT converts plain English requests into complex SQL joins. Claude writes Python ETL scripts that handle edge cases engineers might overlook.
These tools excel at recognizing patterns. Need to flatten nested JSON? The AI writes the transformation instantly. Want to aggregate time-series data? It produces the windowing functions without hesitation. The generated code requires review and often modification, but it eliminates the blank-page problem and provides a solid starting point for development.
The real value emerges in repetitive scenarios. Writing similar transformations across multiple tables, creating boilerplate error handling, or implementing standard logging patterns all become faster with AI assistance. Tasks that once consumed hours now take minutes. Engineers report feeling less fatigued at day’s end because AI handles the tedious parts while they focus on logic and design.
Data prep and ETL automation
Modern ETL platforms use AI to reduce manual pipeline maintenance. AWS Glue DataBrew automatically detects and fixes schema drift. Fivetran’s AI engine handles API changes without breaking data flows. These platforms learn from patterns across their user base to predict and prevent common failures.
The practical impact is significant. Engineers no longer wake up to broken pipelines caused by upstream changes. The AI handles these adjustments automatically, maintaining data flow continuity. This automation shifts engineering effort from reactive fixes to proactive improvements.
Data quality and anomaly detection
AI fundamentally changed data quality monitoring. Traditional approaches required engineers to write explicit rules for every check. AI observability platforms like Monte Carlo learn what “normal” looks like for each dataset and alert only on meaningful deviations.
This shift from rule-based to learning-based monitoring catches issues humans miss. The AI notices when weekend sales patterns suddenly match weekdays, or when a typically stable metric shows unusual variance. It identifies subtle correlations between datasets that manual rules would never capture.
Engineers spend less time writing data quality checks and catch more actual issues that matter to the business. The focus shifts from defining what to monitor to investigating why anomalies occurred and determining their business impact.
Data discovery
Finding relevant data previously required tribal knowledge or extensive documentation. AI-powered catalogs changed this dynamic. Alation’s AI reads query logs to understand how data actually gets used. Collibra automatically generates column descriptions from data patterns. Select Star tracks data lineage without manual mapping.
These tools reduce data discovery time substantially. Engineers no longer maintain sprawling wikis or answer repetitive questions about where data lives. The AI handles documentation and discovery, freeing engineers to focus on building rather than explaining.
Why AI won’t replace data engineers
The most sophisticated AI available today operates like a brilliant intern who memorized every textbook but never worked a day in the field. This gap between theoretical capability and practical application explains why data engineers remain indispensable.
AI lacks deep context and creativity
AI generates code by matching patterns from its training data. It cannot understand why a company chose PostgreSQL over MySQL five years ago, or why certain data must flow through specific compliance checkpoints. These decisions shaped entire architectures that AI cannot comprehend.
Creative problem-solving requires understanding constraints that exist outside the code itself. When a retail company needs to process Black Friday traffic that’s 50x normal volume, the solution involves budget negotiations, vendor relationships, and architectural trade-offs. AI cannot weigh the political cost of delaying a product launch against the technical debt of a quick fix.
The most valuable engineering happens at the intersection of technical possibility and business reality. A data engineer knows when to push back on requirements, when to propose alternatives, and when to accept imperfect solutions. This judgment comes from understanding organizational dynamics that no AI can access.
AI lacks business understanding
Every data project starts with a conversation. Stakeholders describe problems using their own vocabulary, mixing technical terms incorrectly, and often asking for solutions to the wrong problems. A data engineer translates these conversations into actionable technical plans.
This translation goes deeper than parsing requirements. It requires reading between the lines when a VP says “real-time” but means “daily is fine,” or when “all customer data” really means “just these five fields.” Engineers learn to ask the right questions to uncover actual needs versus stated wants. They navigate organizational politics to understand which requirements are negotiable and which are carved in stone.
AI can’t interpret and apply answers in context
Architecture decisions shape organizations for years. Data pipeline architecture determines how information flows through entire organizations. Choosing between batch and stream processing, selecting cloud providers, and designing security boundaries all create ramifications AI cannot evaluate.
Data governance adds another layer of human judgment. Which teams can access sensitive data? How should personally identifiable information be masked? What retention policies balance legal requirements with storage costs? These questions have no objectively correct answers. They require understanding regulatory environments, organizational risk tolerance, and industry practices.
Engineers must also plan for failure scenarios AI cannot imagine. What happens when the primary data center loses power? How should the pipeline handle corrupted files from a trusted partner? These edge cases require creative thinking about problems that haven’t happened yet.
AI fundamentally relies on data engineering
On a very basic level, AI requires data engineers to build and maintain its own applications. Just as data engineers own the building and maintenance of the infrastructure underlying the data stack, they’re becoming increasingly responsible for how generative AI is layered into the enterprise. All the high-level data engineering skills we just described — abstract thinking, business understanding, contextual creation — are used to build and maintain AI infrastructure as well.
And even with the most sophisticated AI, sometimes the data is just wrong. Things break. And unlike a human—who’s capable of acknowledging a mistake and correcting it—I can’t imagine an AI doing much self-reflecting in the near-term.
So, when things go wrong, someone needs to be there babysitting the AI to catch it. A “human-in-the-loop” if you will.
And what’s powering all that AI? If you’re doing it right, mountains of your own first-party data. Sure an AI can solve some pretty menial problems—it can even give you a good starting point for some more complex ones. But it can’t do ANY of that until someone pumps that pipeline full of the right data, at the right time, and with the right level of quality.

In other words, despite what the movies tell us, AI isn’t going to build itself. It isn’t going to maintain itself. And it sure as data sharing isn’t gonna start replicating itself. (We still need the VCs for that.)
Engineers also design quality checks for problems that haven’t occurred yet. They configure SQL anomaly detection rules that catch edge cases specific to their business logic. For instance, they might flag queries that suddenly join tables in unusual ways, detect when stored procedures execute outside normal time windows, or identify when query complexity spikes unexpectedly. They anticipate how data might fail and build safeguards accordingly. This proactive approach requires imagining failure modes that AI, trained on historical data, cannot predict.
What AI means for the future of data engineers
The shift is already visible in job postings. Companies now seek “AI-native” data engineers who can leverage automation tools rather than compete with them. The role is expanding, not shrinking.
Automation will free up more time
The math is simple. Engineers who once spent 60% of their time writing boilerplate code now spend 20%. This reclaimed time flows toward work that actually requires human intelligence.
Complex performance optimization becomes the new normal. Engineers tackle distributed computing challenges that were previously too time-consuming to address. They redesign entire architectures for efficiency rather than patching problems. They build sophisticated monitoring that prevents issues rather than reacting to them.
The parallel to cloud computing is instructive. When AWS eliminated server management, engineers didn’t disappear. They built more ambitious applications. AI automation follows the same pattern, removing drudgery to enable innovation.
New skill areas will appear
Tomorrow’s data engineers need hybrid expertise. Pure SQL knowledge no longer suffices when AI handles basic queries. Engineers must understand how large language models work to use them effectively. They need to know when AI suggestions are trustworthy and when they’re hallucinating.
Cloud architecture expertise becomes non-negotiable. Multi-region deployments, cost optimization, and serverless patterns require deep understanding. Security and privacy knowledge grows critical as regulations multiply globally. Engineers must navigate GDPR, CCPA, and emerging AI governance laws.
The most crucial new skill is prompt engineering for technical tasks. Engineers who can precisely instruct AI tools accomplish far more than those who use them casually. This includes understanding model limitations, crafting effective context, and iterating on results.
Emerging roles will pop up
Specialization is fragmenting the traditional data engineering role. ML Engineers focus exclusively on machine learning pipelines and model deployment. They understand feature stores, model versioning, and inference optimization. DataOps Engineers concentrate on data orchestration, automation, CI/CD for data pipelines, and infrastructure as code. They bridge the gap between data engineering and platform engineering.
Data quality engineers emerge as a distinct specialization. They design comprehensive data quality frameworks, implement observability, and establish SLAs for data products. Data product managers translate between technical teams and business stakeholders, treating data assets as products with roadmaps and user feedback loops.
Collaboration will get better
AI democratizes basic data work across organizations. Marketing analysts write SQL with AI assistance. Product managers modify dashboards without engineering help. This broader participation changes the data engineer’s role fundamentally.
Engineers become platform builders rather than request fulfillers. They create self-service tools with built-in guardrails. They establish templates and patterns that others can safely follow. They focus on enabling others rather than doing all the work themselves.
This shift requires new soft skills. Engineers must become better teachers, explaining complex concepts to non-technical users. They need to design intuitive interfaces and write clear documentation. The most successful engineers will combine deep technical knowledge with the ability to empower others.
What AI will do (probably)
Few data leaders doubt that GenAI has a big role to play in data engineering — and most agree GenAI has enormous potential to make teams more efficient.
“The ability of LLMs to process unstructured data is going to change a lot of the foundational table stakes that make up the core of engineering,” John Steinmetz, prolific blogger and former VP of data at healthcare staffing platform shift key, told us recently. “Just like at first everyone had to code in a language, then everyone had to know how to incorporate packages from those languages — now we’re moving into, ‘How do you incorporate AI that will write the code for you?’”
Historically, routine manual tasks have taken up a lot of the data engineers’ time — think debugging code or extracting specific datasets from a large database. With its ability to near-instantaneously analyze vast datasets and write basic code, GenAI can be used to automate exactly these kinds of time-consuming tasks.
Tasks like:
Assisting with data integration: GenAI can automatically map fields between data sources, suggest integration points, and write code to perform integration tasks.
Automating QA: GenAI can analyze, detect, and surface basic errors in data and code across pipelines. When errors are simple, GenAI can debug code automatically, or alert data engineers when more complex issues arise.
Performing basic ETL processes: Data teams can use GenAI to automate transformations, such as extracting information from unstructured datasets and applying the structure required for integration into a new system.
With GenAI doing a lot of this monotonous work, data engineers will be freed up to focus on more strategic, value-additive work.
“It’s going to create a whole new kind of class system of engineering versus what everyone looked to the data scientists for in the last five to ten years,” says John. “Now, it’s going to be about leveling up to building the actual implementation of the unstructured data.”
How to avoid being replaced by a robot
There’s one big caveat here. As a data engineer, if all you can do is perform basic tasks like the ones we’ve just described, you probably should be a little concerned.
The question we all need to ask—whether we’re data engineers, or analysts, or CTOs or CDOs—is, “are we adding new value?”
If the answer is no, it might be time to level up.
Here are a few steps you can take today to make sure you’re delivering value that can’t be automated away.
- Get closer to the business: If AI’s limitation is a lack of business understanding, then you’ll want to improve yours. Build stakeholder relationships and understand exactly how and why data is used — or not — within your organization. The more you know about your stakeholders and their priorities, the better equipped you’ll be to deliver data products, processes, and infrastructure that meet those needs.
- Measure and communicate your team’s ROI: As a group that’s historically served the rest of the organization, data teams risk being perceived as a cost center rather than a revenue-driver. Particularly as more routine tasks start to be automated by AI, leaders need to get comfortable measuring and communicating the big-picture value their teams deliver. That’s no small feat, but models like this data ROI pyramid offer a good shove in the right direction.
- Prioritize data quality: AI is a data product—plain and simple. And like any data product, AI needs quality data to deliver value. Which means data engineers need to get really good at identifying and validating data for those models. In the current moment, that includes implementing RAG correctly and deploying data observability to ensure your data is accurate, reliable, and fit for your differentiated AI use case.
Ultimately, talented data engineers only stand to benefit from GenAI. Greater efficiencies, less manual work, and more opportunities to drive value from data. Three wins in a row.
How Monte Carlo can help you stand out
Data observability becomes more critical as organizations deploy AI at scale. The complexity of modern data pipelines and the high stakes of AI decisions demand sophisticated monitoring solutions.
Monte Carlo exemplifies how data observability platforms address these challenges. The platform uses machine learning to detect anomalies across data pipelines without requiring manual threshold setting. It monitors data freshness, volume, distribution, and schema changes automatically. When issues arise, the platform traces problems to their root cause and alerts the relevant teams.
Data observability now extends to AI model pipelines. Organizations must track not just traditional data quality metrics but also model inputs, outputs, and performance indicators. Platforms monitor whether training data distributions match production data. They detect when model predictions drift from expected ranges. This comprehensive monitoring prevents AI failures before they impact business decisions.
The integration between data pipelines and AI applications creates new monitoring requirements. A single data quality issue can cascade through multiple AI models and affect numerous downstream applications. Observability platforms must track these dependencies and predict impact across interconnected workflows. They need to distinguish between acceptable variations and genuine problems that require intervention.
Monte Carlo’s approach emphasizes preventing issues rather than reacting to them. The platform learns normal behavior patterns for each pipeline and flags deviations early. This proactive monitoring becomes essential when AI applications depend on consistent, high-quality data. Engineers receive alerts with enough context to understand and resolve issues quickly, maintaining the data reliability that AI applications require.
Embrace AI as a collaborator
AI will augment data engineering work rather than eliminate it. The evidence points clearly toward a future where engineers use AI tools to work more effectively, not one where AI replaces human expertise.
The pattern follows previous technological shifts in our field. Cloud computing eliminated server management but created new opportunities in distributed architecture. Version control automated code tracking but made collaborative development more sophisticated. AI represents another tool that handles routine work while expanding what engineers can accomplish.
Data engineers remain essential for several unchangeable reasons. Organizations need humans to understand business context and translate it into technical solutions. Complex architectural decisions require judgment that weighs multiple factors simultaneously. Data quality standards must reflect real-world requirements that only domain experts can define. These needs will persist regardless of AI advancement.
The path forward requires embracing AI as a collaborator. Engineers who learn to work effectively with AI tools will deliver more value than those who resist change. Upskilling in areas like cloud architecture, DataOps practices, and AI/ML pipelines prepares engineers for evolving responsibilities. Using platforms that automate routine monitoring frees time for strategic work.
The future belongs to data engineers who combine human expertise with AI capabilities. Those who adapt will find their roles more interesting and impactful than ever before. The question was never whether AI would replace data engineers. The real question is how quickly engineers will learn to harness AI’s power to solve bigger, more complex data challenges.
Our promise: we will show you the product.





