The Guide to Data Consistency: How to Find and Fix Data Consistency Issues

Table of Contents
Your CEO walks into the Monday morning meeting armed with dashboard screenshots. “Why does our revenue dashboard show $12M for Q4, but the board deck you sent Friday says $10.8M?” The room goes silent. The head of analytics starts cross-referencing spreadsheets. The data engineer pulls up SQL queries. Finance frantically checks their calculations. This scenario plays out in conference rooms everywhere, and it’s not just about embarrassing moments in executive meetings.
When your customer count is different in Salesforce versus your data warehouse, when marketing’s definition of “active user” doesn’t match product’s, or when that critical KPI shows three different values depending on where you look, you don’t just have a data problem. You have a trust problem. Data consistency might sound like a dry, technical concept that only database administrators worry about. But inconsistent data is costing your organization real money through wasted hours reconciling numbers, missed opportunities from flawed decisions, and the slow erosion of confidence in your entire data stack.
That expensive modern data platform you built? It’s only as valuable as the trust people have in it. The good news is that data consistency is a solvable problem. You don’t need to rip and replace your entire infrastructure or hire an army of data engineers. What you need is a systematic approach to identifying where consistency breaks down, understanding why it happens, and implementing the right mix of technical and organizational practices to keep your data in sync.
In this article, we’ll cut through the complexity and show you exactly how to achieve and maintain data consistency across your organization. No theoretical hand-waving, just practical strategies that work in the real world, where data is messy, teams move fast, and perfection isn’t the goal. Trustworthy data is.
What is Data Consistency?
Data consistency refers to the accuracy and uniformity of data stored across multiple databases, tables, or replicas. It ensures that if a piece of data changes in one location, it updates everywhere that data appears. This uniformity creates a single version of truth across your entire data infrastructure.
Consistency means no contradictions. When a customer updates their phone number in your CRM, that same number should appear in your billing platform, marketing database, and support ticketing tool. Every query, report, or analysis should reflect the same value, regardless of which dataset you’re accessing.
Consider this scenario. A customer moves and updates their address in your billing portal. In a consistent data environment, this change immediately reflects in your shipping database, preventing packages from going to the old address. In an inconsistent environment, the shipping team works with outdated information, leading to delivery failures and frustrated customers.
But consistency extends to more than matching values. It includes format consistency, where dates follow the same structure everywhere (YYYY-MM-DD, not a mix of formats). It encompasses semantic consistency, where metrics like “monthly active users” have one definition across all teams. When marketing calculates MAU one way and product calculates it differently, you don’t just have different numbers. You have different realities that undermine decision-making.
Data Consistency vs. Data Integrity
Data consistency often gets confused with related concepts like data integrity and data accuracy. While they’re connected, they address different aspects of data quality.
Data consistency focuses on uniformity and synchronization across databases and platforms. When your customer’s email is the same in every database, that’s consistency. Data integrity encompasses the overall accuracy, completeness, and trustworthiness of data throughout its lifecycle. It’s a broader concept that includes consistency as one component.
Accuracy differs from both. A customer’s phone number can be consistent across all platforms but still be wrong if it was entered incorrectly everywhere. That’s consistent but inaccurate data. Conversely, one database might have the correct phone number while others have outdated versions. That’s accurate in one place but inconsistent overall.
These distinctions matter for troubleshooting. If reports show different values for the same metric, you have a consistency problem. If all reports show the same incorrect value, you have an accuracy problem. If data is missing required fields or violates business rules, you have an integrity problem. Each requires different solutions.
The Benefits of Consistent Data
Consistent data is the backbone of effective data analysis and decision-making. Without it, you wouldn’t have key benefits like:
Reliability
Like a dependable instrument in our orchestra, consistent data plays the right notes at the right time. It allows us to trust our data and the insights derived from it.
Efficiency
Consistent data reduces the time spent checking, cleaning, and reconciling data. This frees up resources for more valuable tasks, like analysis and strategy.
Accuracy
With consistent data, our analyses and reports reflect reality more accurately. This supports better, more informed decision-making.
Interoperability
Consistent data can be easily combined and compared with other data sets, enabling more comprehensive insights.
Consequences of Inconsistent Data
When data consistency breaks down, the effects ripple through your entire organization. These aren’t minor inconveniences. They’re expensive problems that erode trust and destroy productivity.
Poor Decision-Making
Inconsistent data leads directly to flawed strategic choices. One dashboard shows revenue trending upward while another shows it flat. Customer acquisition costs vary depending on which report you check. Marketing celebrates a successful campaign based on their metrics while finance sees no impact in theirs. When executives make decisions using contradictory data, those strategies are built to fail. Companies end up investing in the wrong initiatives, missing real problems, and celebrating false victories.
Wasted Time and Resources
Teams burn countless hours resolving discrepancies rather than creating value. Data engineers hunt through pipelines trying to identify where numbers diverged. Analysts build reconciliation reports to explain mismatches. Entire meetings get consumed debating whose numbers are correct instead of discussing what actions to take. A simple question like “What’s our conversion rate?” turns into a multi-day investigation. This expensive damage control drains resources that could drive innovation.
Erosion of Trust
Trust disappears quickly once stakeholders catch inconsistencies. Many CEOs still rely on gut instinct over data analytics when inconsistencies appear. Once people lose faith in the data, years of building a data-driven culture can unravel in weeks. Teams revert to opinion-based decisions because they can’t trust what they’re seeing. The damage extends beyond individual decisions. It undermines the entire data infrastructure investment.
Limited Analytical Capabilities
Inconsistent data creates analytical dead ends. When values conflict or formats differ, datasets can’t be joined or compared effectively. Customer journeys remain incomplete because identifiers don’t match across platforms. Product performance stays siloed from support metrics. Revenue analysis can’t incorporate marketing spend data. These integration failures prevent organizations from discovering the patterns and connections that drive breakthrough insights. Instead of a unified view, you get isolated islands of information.
Challenges in Achieving Data Consistency
Even when organizations recognize the importance of consistency, achieving it proves difficult. Modern data environments face several persistent obstacles that make maintaining consistency an ongoing battle.
Data Silos and Fragmentation
Different departments and tools create isolated data stores with their own standards and processes. Marketing maintains customer records in HubSpot. Sales tracks the same customers in Salesforce. Support manages them in Zendesk. Each platform evolves independently, developing its own version of truth. A customer updates their email in one tool, but the change never reaches the others. These silos multiply as organizations adopt more specialized tools, each adding another potential consistency breaking point.
Lack of Standard Definitions
Without clear, shared definitions, teams interpret data differently. One team’s “active user” is another team’s “engaged user.” Revenue might include taxes in one report and exclude them in another. Customer segments get defined differently across departments. These ambiguities mean that even perfectly synchronized data produces inconsistent results. Teams think they’re measuring the same thing, but they’re actually tracking completely different metrics.
Manual Processes and Human Error
Heavy reliance on manual data entry and reconciliation introduces constant inconsistencies. Someone enters “New York” while another types “NY.” An analyst copies data into a spreadsheet and transposes two digits. A data engineer maps the wrong field during a migration. These mistakes compound quickly. Manual processes can’t scale, and human attention wavers. Every manual touchpoint becomes a vulnerability where inconsistency creeps in.
Constant Changes and Integrations
Schema changes, platform migrations, and new data sources continuously threaten consistency. A product team restructures the database. A new SaaS tool gets added to the stack without proper integration. Business rules update in one application but not others. An API changes its response format. Each modification requires careful coordination to maintain consistency, but that coordination often doesn’t happen. Teams move fast and consistency becomes collateral damage.
Cultural and Skill Gaps
Variations in data literacy and governance practices across teams create inconsistent approaches. Some teams rigorously validate and clean their data. Others don’t. One department documents every change while another operates without documentation. Technical teams might understand consistency requirements while business users don’t. These cultural differences mean that even with the right tools and processes, consistency breaks down at the human level.
Real-World Examples of Data Consistency Challenges
Data consistency challenges affect every industry, with tangible impacts on operations and outcomes.
Healthcare
Patient data must remain consistent across hospital databases and electronic health records. When allergy information in the emergency department differs from what appears in the pharmacy database, it creates life-threatening risks. Inconsistent medical histories lead to misdiagnoses, duplicate tests, and regulatory compliance failures. A patient’s blood type recorded differently across departments could result in fatal transfusion errors.
Finance
Banks require absolute consistency in transaction data across all platforms and replicas. When account balances don’t match between the mobile app and core banking platform, customers lose trust immediately. Inconsistent transaction records lead to double charges, incorrect overdraft fees, and regulatory penalties. Financial institutions face millions in fines when reporting inconsistencies violate compliance requirements.
Retail
Inventory data must align between online stores and physical locations. When the website shows items in stock but the warehouse database says otherwise, orders get canceled after customers pay. This inconsistency drives customer complaints, negative reviews, and lost sales. Major retailers have faced public backlash when Black Friday sales showed available inventory online that didn’t actually exist.
How to Fix and Maintain Data Consistency
Once you’ve identified inconsistencies or want to prevent them proactively, these practices ensure data stays consistent across your entire infrastructure. Success requires both technical solutions and cultural commitment.
Eliminate Data Silos
Break down silos by funneling critical data into a central data warehouse or lake that serves as the authoritative source. When all teams pull from the same repository, contradictions disappear. This doesn’t mean copying everything into one massive database. It means establishing clear data flows where updates propagate predictably through your infrastructure.
Implement a unified data catalog or master data management approach for key entities. Define which database owns each piece of data and make that ownership explicit. When customer data lives in your CRM as the primary source, every other tool should read from or sync with that source, not maintain its own version. Internal collaboration and data sharing agreements between teams help reinforce this single source of truth principle.
Define and Document Data Metrics and Schemas
Create a data dictionary and semantic layer so every team uses identical definitions. Lock in metric calculations using tools like dbt or LookML. When you define “monthly recurring revenue” in your semantic layer, that becomes the only definition. This prevents scenarios where two analysts calculate MRR differently and produce conflicting reports.
Documentation proves as important as technology. Maintain an accessible, regularly updated glossary of all data definitions, business rules, and calculation methods. When both engineers and analysts know exactly what each field means and how metrics get calculated, consistency follows naturally. Communication about these standards matters as much as the standards themselves.
Implement Data Validation Rules
Establish validation checkpoints at data ingestion and before data enters critical databases. Use schema validation and data contracts to reject inconsistent records before they contaminate downstream processes. This acts like quality control on an assembly line, catching defects before they spread.
For example, if customer IDs should be unique across tables, enforce that rule programmatically. When data arrives in an unexpected format or violates business rules, block it and alert the responsible team. These validation rules should be comprehensive, covering data types, formats, ranges, and referential integrity. The goal is making bad data impossible to enter rather than trying to fix it later.
Automate Monitoring and Alerts
Set up continuous data observability across your pipelines. Automated monitoring acts as a 24/7 watchdog for consistency issues. If record counts suddenly drop between source and destination, if schemas change unexpectedly, or if key metrics deviate from normal patterns, you get immediate alerts.
Modern AI observability platforms learn your data’s normal patterns and detect anomalies automatically. They can identify when revenue figures between platforms start diverging or when data freshness degrades. These tools scale to monitor thousands of consistency rules simultaneously, something manual processes could never achieve. When alerts trigger, teams can intervene before stakeholders notice problems in their dashboards.
Establish Ownership and Governance
Assign clear data stewards for critical datasets who take responsibility for maintaining consistency. These owners oversee schema changes, coordinate between teams, and enforce governance policies. They run regular audits, manage data quality metrics, and serve as the final authority on data definitions and standards.
Strong governance includes regular sync checks, standardized change management processes, and clear escalation paths for consistency issues. Data stewards should have both the authority to enforce standards and the accountability for consistency metrics. This human element proves essential because technology alone can’t solve organizational and communication challenges.
Maintaining consistency requires ongoing effort. It’s not a project you complete but a discipline you practice. Combine these technical and organizational practices to build a foundation of trustworthy, consistent data.
How to Identify Inconsistencies and Ensure They Never Happen
Inconsistencies can happen due to a variety of reasons such as human errors during data entry, system glitches, mistakes during data migrations, disparate data sources having different formats, or changes in data over time that are not properly updated across all systems.
To track down and handle inconsistencies lurking in our data we need to deploy several strategies.
- Remove Data Silos: Data silos are the enemy of data consistency as they prevent a unified view. A common example of this is in the marketing domain. If digital marketers are accessing Marketo and Salesforce for information on a campaign, they may not match. This could be the result of a sync issue, the type of information each collects, or how each platform treats different data types. Having the data warehouse as a central source of truth can help present a more consistent view of the campaign.

Screenshot of Monte Carlo’s data profiling feature, which can help with data consistency. - Data Profiling: Profiling a dataset can reveal its typical behavior, which is helpful for identifying when those become anomalous in a way that might create issues with data consistency. Is a column never NULL? What is its cardinality? Is the data type a float or a varchar? What are the maximum and minimum values? This type of data audit involves examining individual attributes, looking for patterns, outliers, and anomalies that might indicate inconsistencies.
- Understand and Document the Context: Data engineers may not always have the full business context behind a dataset. Not understanding the semantic truth can impede data consistency efforts. Chad Sanderson, the former head of data at Convoy, shared an example where the “concept of shipment_distance could be very different depending on the dataset. ‘Distance’ could be the delta between the starting facility and end facility in miles or hours, it could refer to the actual driving time of a carrier (accounting for traffic, pit stops, etc), it could include the number of miles a trucker spends driving TO and FROM the pick-off and drop-off point, it could refer to the length of the ROUTE (a separate entity with its own ID) and so on and so forth.”
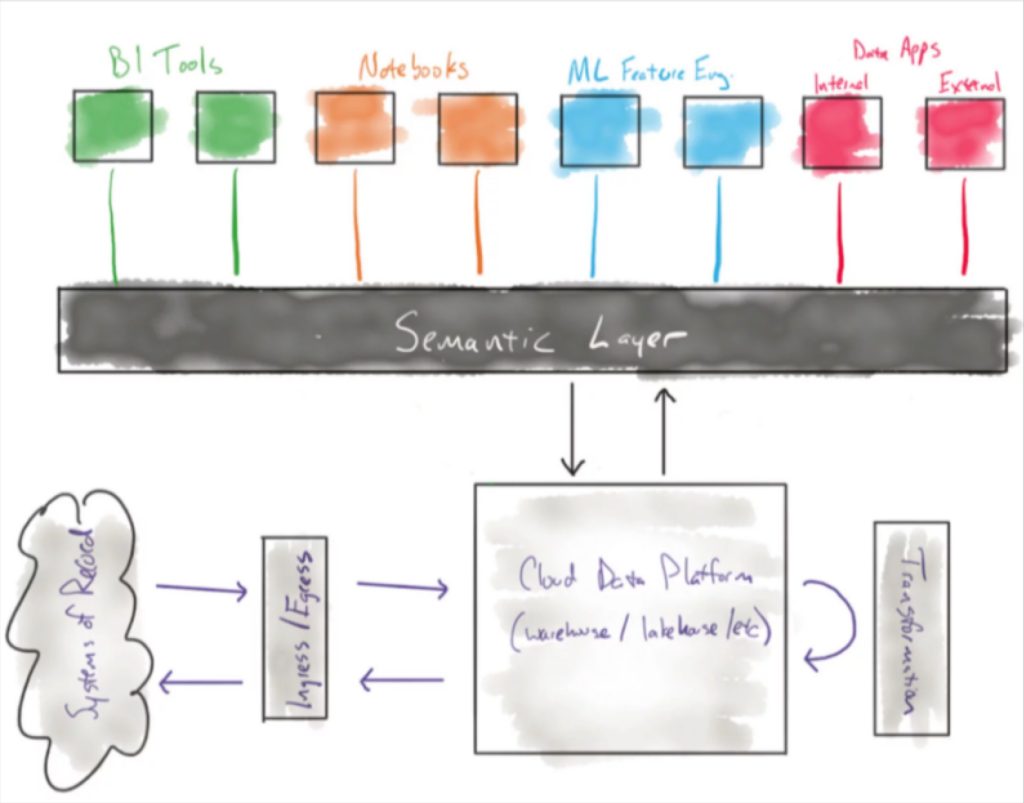
A semantic layer can help with data consistency. - Create a Semantic Layer: Once you have defined your key metrics it’s time to lock them down so they can be leveraged by the entire organization. dbt, the central tool within the transformation layer where most metrics are built, is a natural place to start building a semantic layer. Looker also has a semantic layer called LookML.
- Data Validation: Like a tuning fork ensuring our instruments are at the right pitch, data validation checks that incoming data meets certain criteria, catching data consistency issues before they enter our system. Implementing data contract architectures can also help prevent bad data from ever entering the data warehouse.
- Automated Data Monitoring: Think of data quality monitoring as our orchestra’s conductor, keeping an eye (or ear) on the overall performance and stepping in when something’s not right. Data monitors can catch inconsistencies, like unexpected schema changes or anomalous values, and alert us to their presence, allowing us to address them swiftly.
- End-to-End Pipeline Monitoring Business logic and metric definitions are executed in dbt models and SQL queries. Having a data observability platform that is able to monitor your data pipeline from ingestion to visualization, and can pinpoint how changes in dbt models or query changes may have impacted data consistency, can be a big help.
Monte Carlo is a powerful tool in the fight for data consistency
Managing consistency across dozens of data sources and platforms manually isn’t just difficult, it’s practically impossible without a small army of engineers dedicated to nothing but data reconciliation. And even then, you’re asking talented people to spend their days on tedious validation work instead of building valuable insights
Fortunately, that’s where the data observability platform Monte Carlo steps in. Monte Carlo monitors and alerts you of data consistency and broader data quality issues before you even knew you had them. Using machine learning, the platform doesn’t just passively monitor; it actively learns about your data environments using historical patterns, detecting anomalies, and triggering alerts when pipelines break or anomalies emerge.
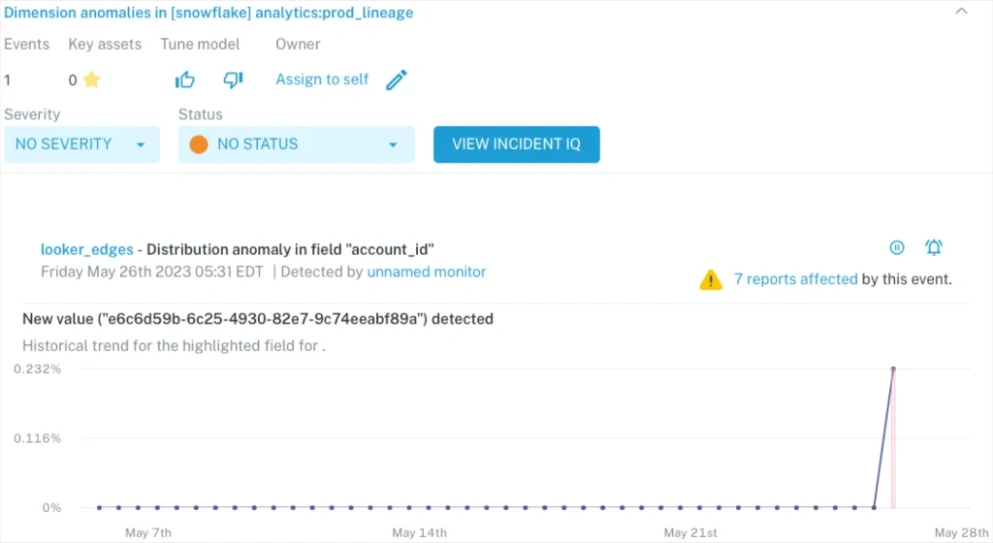
If you’re looking for a maestro to guide you through the intricacies of data consistency, consider Monte Carlo. It’s like a crystal ball and a conductor’s baton rolled into one, giving you the visibility and control you need to maintain your data symphony’s harmony. To see it in action, don’t hesitate to request a demo and experience it firsthand.




